Consider this scenario: Your organization has made significant investments in an advanced Retrieval-Augmented Generation (RAG) system. You possess state-of-the-art embedding models, sophisticated retrieval algorithms, and ample GPU resources that satisfy any data scientist. Nevertheless, your Generative AI applications continue to deliver subpar responses, overlook crucial contextual information, and cause user frustration due to irrelevant outputs.
Does this sound familiar? The unvarnished reality is that the issue does not lie in your chunking methodology or the selection of your large language model; rather, it lies in the preliminary stage before chunking. While the AI community predominantly focuses on techniques for chunking and retrieval, we have been neglecting the essential groundwork that determines the success or failure of our Generative AI applications. This foundational element is document partitioning and preprocessing, an advanced process that converts disorganized, unstructured documents into structured data suitable for AI processing.
The great GenAI blind spot
Most GenAI practitioners treat document preprocessing as a simple text extraction step. They assume that pulling text from PDFs and feeding it to chunking algorithms is sufficient. This assumption is not just wrong; it's costing organizations millions in lost productivity and failed AI initiatives.
The reality is far more sophisticated. Before any effective chunking can occur, documents must undergo a complex transformation process that involves:
Element Detection and Classification: Identifying different document element types
Layout Analysis: Understanding visual hierarchies and spatial relationships
Structural Preservation: Maintaining semantic relationships between headers, content & metadata
Context Enhancement: Enriching elements with positional and hierarchical information
The hidden genius
If there’s one breakthrough powering the next generation of GenAI document workflows, it's this: precise element detection and classification. More than any other preprocessing step, it converts a document from an unreadable blob into a structured, context-rich information engine.
Headings/Subheadings: Often marked by HTML <h1>-<h6> tags or visual cues (large, bold font).
Paragraphs/Narrative Text: Runs of prose, typically separated by blank lines or <p> tags.
Lists: Lines starting with bullets or numbers (- , •, 1., etc.).
Code Blocks: Monospaced text or fenced blocks (e.g. lines indented or between triple backticks).
Tables: Structured rows/columns, often detected via cell patterns or table tags.
Images and Figures: Usually <img> tags or detected bounding boxes, possibly with captions.
Other Blocks: Captions, footnotes, blockquotes, etc.
Element detection lets AI see, not just read
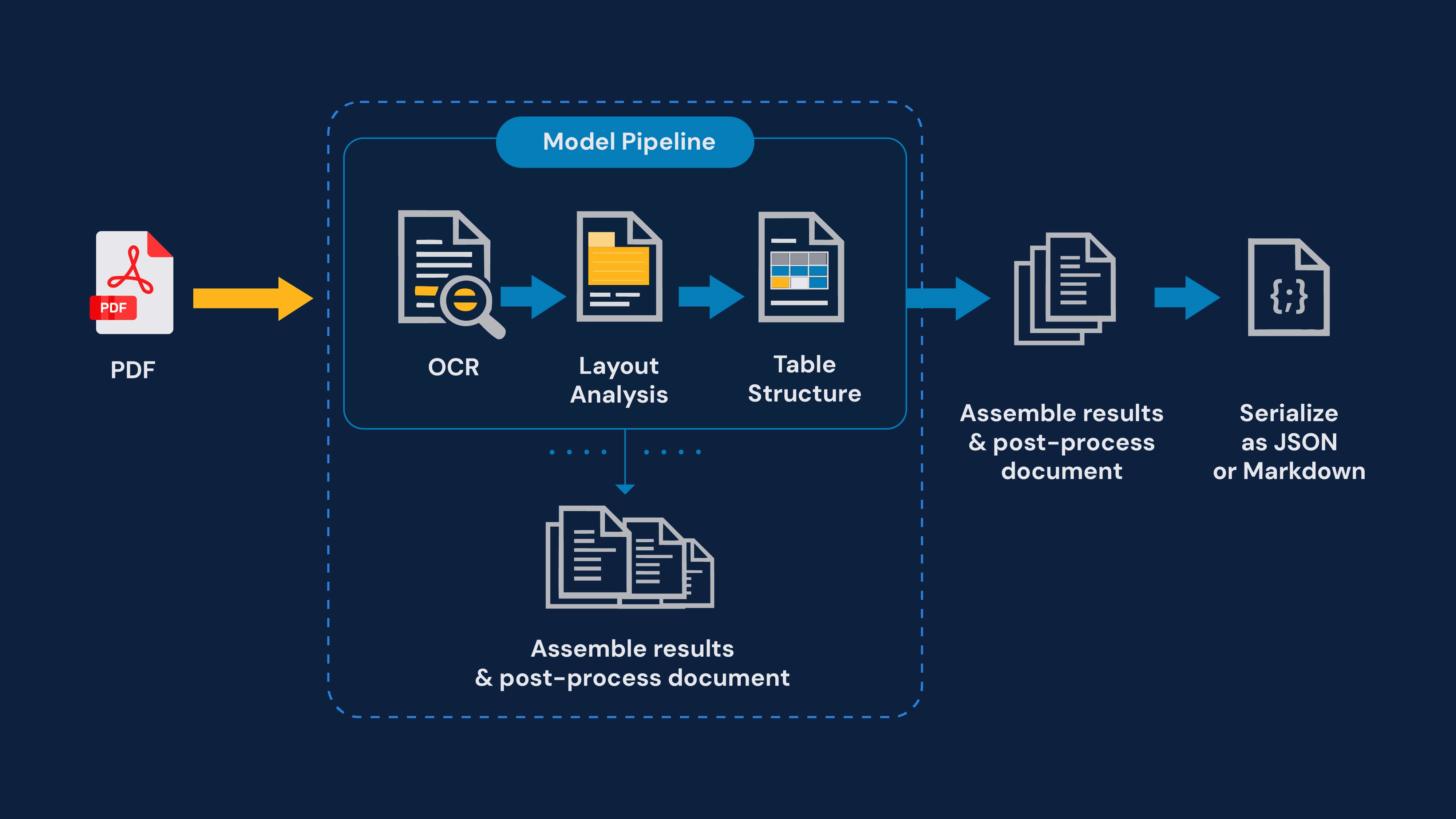
The Element Detection & Classification processing pipeline begins with raw document ingestion; formats such as PDF, HTML, DOCX, or text are converted into a unified intermediate representation. The pipeline then performs element segmentation, identifying logical blocks like titles, headers, paragraphs, tables, lists, images, and code snippets using a mix of heuristics, layout parsers, and vision-based models.
Each detected block is then passed through a classification layer, which assigns a semantic label (e.g., “Heading-Level-2”, “Narrative-Text”, “Table”, “Figure”) along with confidence scores and positional metadata (coordinates, page number, or order index).
The outputs of this stage are structured element objects or JSON dictionaries, each containing fields such as id, type, content, coordinates, and metadata. The output format typically conforms to JSON, Parquet, or database table schemas, making it easily consumable by downstream processes such as layout analysis, chunking, or embedding generation. In essence, this pipeline transforms unstructured raw content into a semantically organized dataset, a machine-readable blueprint of the document’s logical structure.
Illustrative example: With vs without element detection
Let’s take a simple invoice document as input.
Invoice #2345 Date: 03/10/2025 Customer: Acme CorpItems: Widget A - $120, | ["Invoice #2345 Date: 03/10/2025 Customer: Acme Corp Items: Widget A - $120, Widget B - $200 Total Amount: $320 Thank you for your business!"] | [ {"type": "Header", "content": "Invoice #2345", "class": "DocID"}, {"type": "Metadata", "content": "Date: 03/10/2025"}, {"type": "Entity", "content": "Customer: Acme Corp"}, |
Raw Input | Without element detection When data is directly chunked or embedded without detecting elements, the system treats all tokens as a flat sequence | Without element detection Now, each chunk carries semantic and positional awareness, enabling retrieval pipelines or LLM fine-tuning processes to maintain context fidelity and type-level embeddings. |
Why it supercharges GenAI results
Unlocks section-specific reasoning: With every title, table, or list tagged and separated, retrieval and answering become section-aware, making GenAI output precise for business context, compliance, or deep technical queries.
Preserves purpose: Tables are treated as structured data, not line noise; figures get their captions; references stay glued to the facts. No more junk chunks or context loss.
Enables rich filtering: Need only the tabular financials from a technical report? Or code snippets from a manual? Element classification enables instant, robust linking of query capabilities to document intelligence.
Practical and future-proof
Works for PDFs, Word docs, HTML, and even images/OCR, universally adaptable, future-facing.
Libraries like Docling, Unstructured, MarkItDown make this actionable with just a few lines of Python, allowing rapid prototyping and production deployment.
Sets the stage for downstream upgrades: once elements are detected, all other enhancements (layout, structure, context) build naturally, but without #1, all bets are off.
Conclusion
Element detection and classification is the engine behind document intelligence. Don’t let critical context and structure evaporate. Treat every document as a bundle of elements, from headers to tables and beyond, so your AI can reason, retrieve, and explain like a true enterprise expert.
Make it your default “first step”; no GenAI pipeline should operate without it. And when the team asks, “What really drives results?” show them your element detection module…it’s where the magic happens.





