Closing the capability-viability gap: An enterprise framework for operationalizing agentic AI at scale
By Raj Arun
Enterprise AI is evolving from single-turn text generation to agentic systems that reason, plan, and execute multi-step workflows. Yet realizing this potential requires models with deeper reasoning, longer context, and reliable tool use demands that increase compute costs, raise latency, and introduce governance constraints.
Across deployments in healthcare, financial services, and manufacturing, Fractal identified a recurring constraint called the capability-viability gap. Think of this as a divide between AI systems capable of complex reasoning and those meeting the economic and regulatory standards of production.
Fractal's capability-viability assessment framework
To systematically diagnose this challenge, Fractal developed the capability-viability assessment framework. This strategic tool is a result of refinement across deployments in regulated industries and large-scale enterprise environments.
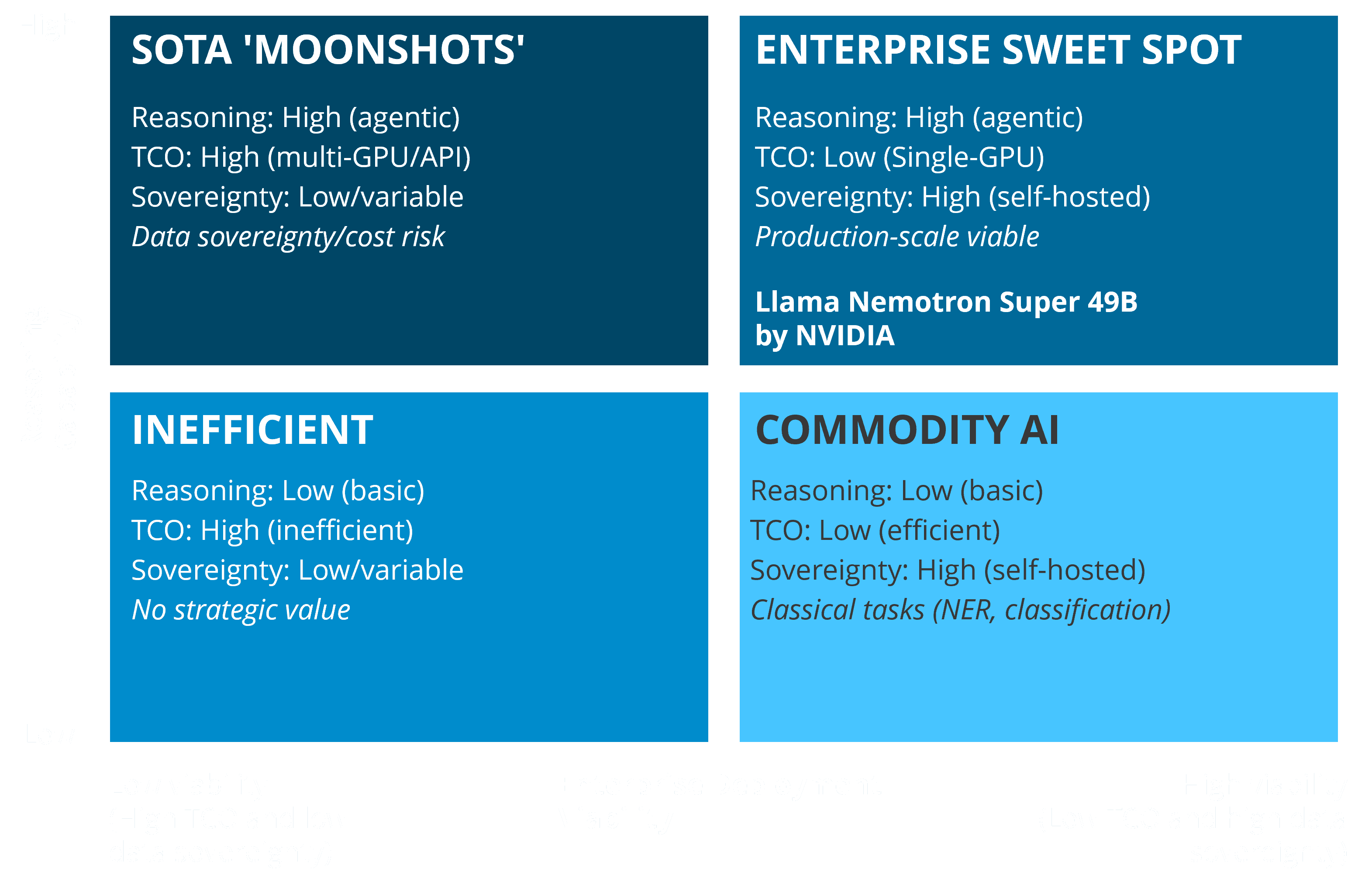
This framework maps AI systems across two critical dimensions that determine deployment success:
Reasoning capability refers to what an AI system needs to handle complex, multistep agentic workflows. It involves the technical depth required for tasks such as multi-turn tool use, retrieval-augmented generation, and context-aware decision-making across enterprise processes.
Enterprise deployment viability brings together economic feasibility (can you operate this at scale within TCO targets?) and data sovereignty (can you legally deploy this given regulatory requirements?). Many AI strategies fail on this second dimension. Viability isn't just about cost. It depends on meeting both conditions together.
This dual-axis view produces four strategic positions that explain common decision traps organizations face.
The four strategic positions
Enterprise sweet spot (top-right): Models that combine reasoning with high viability. They meet single-GPU economics and self-hosting requirements, representing the ideal balance of capability and deployment practicality.
State-of-the-art (SOTA) 'moonshots' (top-left): Advanced models that excel in capability but fail viability tests. They need multi-GPU setups or rely on third-party APIs. This makes these models unusable despite their power.
Commodity AI (bottom-right): Smaller 7B-13B models optimized for low-cost, repetitive tasks. They are self-hostable and efficient but lack the depth for complex, multistep reasoning.
Inefficient (bottom-left): Legacy or poorly optimized architectures offering neither capability nor economic advantage. This quadrant has no strategic value.
Why this framework matters
Organizations deploying agentic AI often face a trade-off. They can either adopt capable models that are economically or regulatorily unviable (SOTA Moonshots) or use viable models that lack the reasoning power required for transformative work (Commodity AI).
The goal is to break this trade off by building an operating model that balances capability and viability at the same time.
A tiered approach that aligns models with deployment realities
NVIDIA's tiered model family offers practical alignment between business needs and deployment reality.
Tier | Typical parameter size | Parent model lineage | Target hardware/ deployment | Primary use case |
|---|---|---|---|---|
Nano | 4B-12B | Llama 3.1 8B | Edge devices, PCs, single consumer GPU | Edge devices and single consumer GPUs for low-latency or on-device scenarios. |
Super | 49B | Llama 3.3 70B | Single data center GPU (e.g., H100/H200) | Designed for a single data center GPU (H100 or H200) to support mainstream enterprise agents. |
Ultra | 253B | Llama 3.1 405B | Multi-GPU data center servers | Tailored for multi-GPU systems when maximum accuracy is the priority. |
For businesses that need smart AI without high costs, the Llama 3.3 Nemotron Super 49B model is a practical choice. It offers advanced reasoning similar to much larger models but runs efficiently on a single server.
Architectural choices that enable single-GPU economics with competitive capability
The 49B system uses neural architecture search (NAS) to break a 70B teacher model into efficient blocks, then assembles them for optimized throughput on single H100 GPUs. Here are key techniques that enable this:
Quantization: Lower-precision numbers during inference to reduce memory and compute while maintaining accuracy.
KV cache optimization: The key-value (KV) cache acts as short-term memory for conversations but consumes GPU memory. Optimizing this is critical for single-GPU deployment.
Variable architecture: Selectively replacing self-attention layers with linear layers and using variable feed-forward ratios allocates parameters where they matter most.
To convert model capability into enterprise value, organizations need post-training alignment and operational controls.
Post-training uses supervised fine-tuning and reinforcement learning to prepare the system for enterprise tasks like math, coding, and tool use, improving reasoning depth, and reliability.
Operational controls make advanced reasoning practical and economically viable in production. The reasoning toggle (“/no_think”) lets teams disable costly reasoning for simple tasks so compute cost aligns with task complexity. Evidence of fit through benchmarks validates performance, confirming that a right-sized system can deliver capability without breaking TCO targets.
Governance and deployment patterns that keep sensitive data under enterprise control
Effective governance keeps AI systems compliant and under enterprise control. In Fractal’s framework, viability rests on three pillars: sovereignty, commercial clarity, and operational tooling. This ensures models run securely within the organization’s environment.
Open model weights for fine-tuning and deployment on-premises or in private cloud environments.
Permissive licensing (NVIDIA Open Model License) intended for commercial enterprise use.
Enterprise framework (NVIDIA NeMo) for secure customization, data curation, fine-tuning, and policy guardrails.
This architecture turns deployment from a research project into an IT exercise.
Deployment as managed infrastructure
Operationalizing agentic AI requires deployment models that simplify integration and reduce overhead while enabling continuous improvement. NVIDIA’s packaged microservices (NVIDIA inference microservices) accelerate production by bundling optimized models with APIs, cutting manual tuning and aligning with familiar DevOps practices. This architecture supports a feedback loop for ongoing refinement, creating self-learning systems that adapt to enterprise needs.
Fractal strengthens this approach with observability, safety reviews, and red team exercises to ensure technical gains translate into measurable business outcomes.
How economics improve when capability and simplicity meet on a single GPU
The economic case follows directly from the architecture and operating model.
Single-GPU deployment avoids the complexity and cost of multi-GPU setups.
Higher throughput and lower latency on one server improve unit economics and service levels.
Fewer servers cut power and cooling needs, reducing total cost of ownership.
Predictable scaling enables accurate capacity planning, giving teams clear cost per session before deployment.
When combined with sovereignty and control, these factors turn advanced reasoning from a lab experiment into a scalable production service. Achieving 70B-class capability on a single GPU marks a fundamental shift in what is economically feasible for enterprise agentic AI.
Fractal's operationalization framework: From assessment to production
Agentic AI should operate as a managed capability rather than a one-off build. Fractal recommends using a structured assessment methodology that evaluates both dimensions of the capability-viability framework before any infrastructure commitments.
The four-checkpoint assessment
This framework provides the foundation, but the detailed scoring rubrics, risk matrices, and decision trees are calibrated through consulting engagement to fit each industry’s specific requirements:
Business outcomes: Define clear workflow goals and link success metrics to business KPIs, not just model accuracy.
Sovereignty and risk: Verify data residency, audit trails and model change controls. In regulated industries, this step determines which models are allowed. API-based options may be ruled out early.
Unit economics: Estimate cost per session, throughput per server, and the impact of reasoning modes on spend. Model total cost of ownership to confirm economic viability at scale.
Performance validation: Test models on real enterprise tasks before rollout. Domain benchmarks often reveal gaps that general ones miss.
Implementation insights from enterprise deployments
Enterprises that successfully operationalize agentic AI follow a playbook that enables them to achieve real business outcomes:
Start with the enterprise sweet spot: Prove value on single-GPU deployments to reduce technical risk and financial exposure during validation.
Scale selectively: Not every workflow needs full reasoning. Use the reasoning toggle and model sizing wisely.
Measure continuously: Build observability from the start. Track technical metrics like latency and throughput, and business metrics like task completion and decision quality.
Plan for the data flywheel: Capture interaction data, corrections and edge cases. Continuous learning from production feedback drives compounding value and competitive advantage.
Conclusion
Agentic AI scales only when capability meets viability. This requires right-sized architectures that are discovered through neural architecture search, alignment programs focused on enterprise tasks, and operating stacks running inside enterprise environments.
The question is no longer whether to deploy agentic AI, but how to deploy it in real enterprise settings. Fractal's framework provides strategic evaluation for AI investments by identifying where systems fall on this map and how to move them toward the enterprise sweet spot.
Recent Blogs

