Context Engineering with OpenAI: Making Enterprise AI Agents Production-Ready
Most LLM demos feel magical, but the same model often falters in real-world complexity. A chatbot might flawlessly draft an email or book travel, giving the impression it “understands” everything. But in practice, it quickly forgets what was said earlier, can’t access needed internal data, and starts guessing instead of truly reasoning. In short, what works in a demo can fail in production, and the difference isn’t just a bigger model; it’s how the model manages context.
As organizations transition from experimenting with Large Language Models (LLMs) to deploying autonomous agents, the constraint is shifting from raw model intelligence to context discipline.
At Fractal, we have observed that the most capable agents aren’t defined by the size of their prompt, but by the precision of their environment. This discipline, “Context Engineering,” is the architectural practice of controlling what an agent knows, retrieves, and reasons over at every millisecond of an interaction.
OpenAI’s latest platform capabilities make that discipline far more practical, from the Responses API for stateful multi-turn execution to GPT-5.4 for stronger reasoning and tool use, along with built-in capabilities such as web search, file search, computer use, connectors, and MCP-based integrations. With the right retrieval strategy, summarization approach, and guardrails, agents move beyond demo quality and become reliable enough for enterprise workflows.
Why context engineering is the new engineering frontier
The early phase of enterprise AI was shaped by stateless interactions: a prompt went in, an answer came back. That model is no longer sufficient for real operational workflows.
Modern enterprise workflows involve interactions that span hundreds of turns, trigger dozens of API calls, and must adhere to strict compliance and governance standards. In that setting, performance depends on more than just model quality. It depends on whether the system can provide the right instructions, the right memory, the right data, and the right access to tools at the right step in the workflow.
Even with the latest OpenAI Models with a massive context window, simply framing the prompt is not sufficient. An agent may generate outdated or incorrect answers (destroying user trust) or divulge information it shouldn’t (violating policy and causing legal trouble). It can also become difficult to trace why a decision was made if context is assembled inconsistently. For enterprise teams, those are engineering and governance issues, not just prompting issues. This “black box” opacity is unacceptable in an enterprise setting. Having a deliberate context strategy dramatically reduces these business risks.
Context Engineering reframes the problem: it is the art of curating the optimal token set for a specific reasoning step. Context must be governed, pruned, and optimized throughout the agent’s lifecycle.
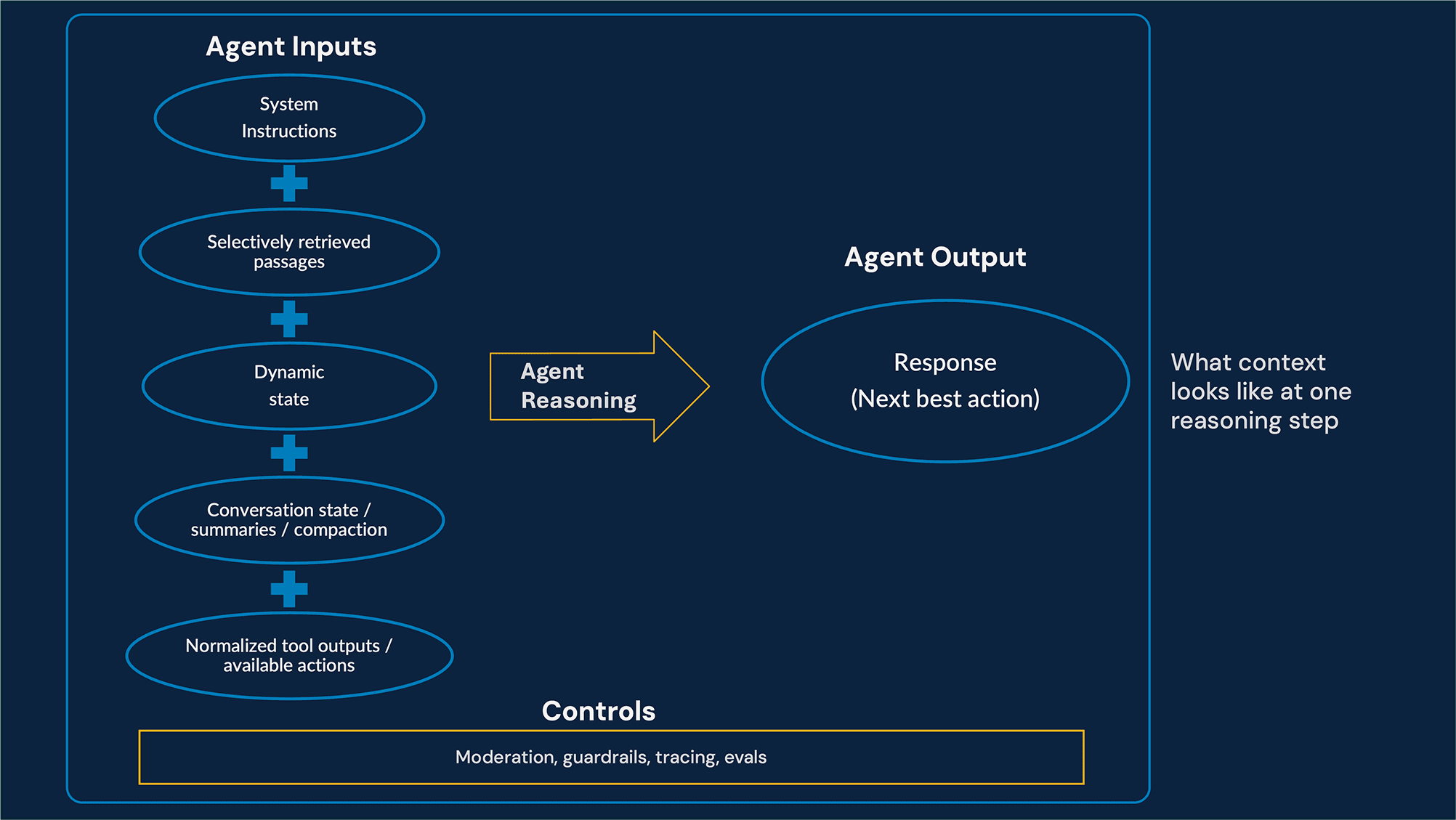
The “context-first” framework
To evolve from mere “prompting” to “production,” we employ a structured Five-Layer Context Architecture. This framework organizes information by role and lifecycle, ensuring the agent operates at the appropriate level.
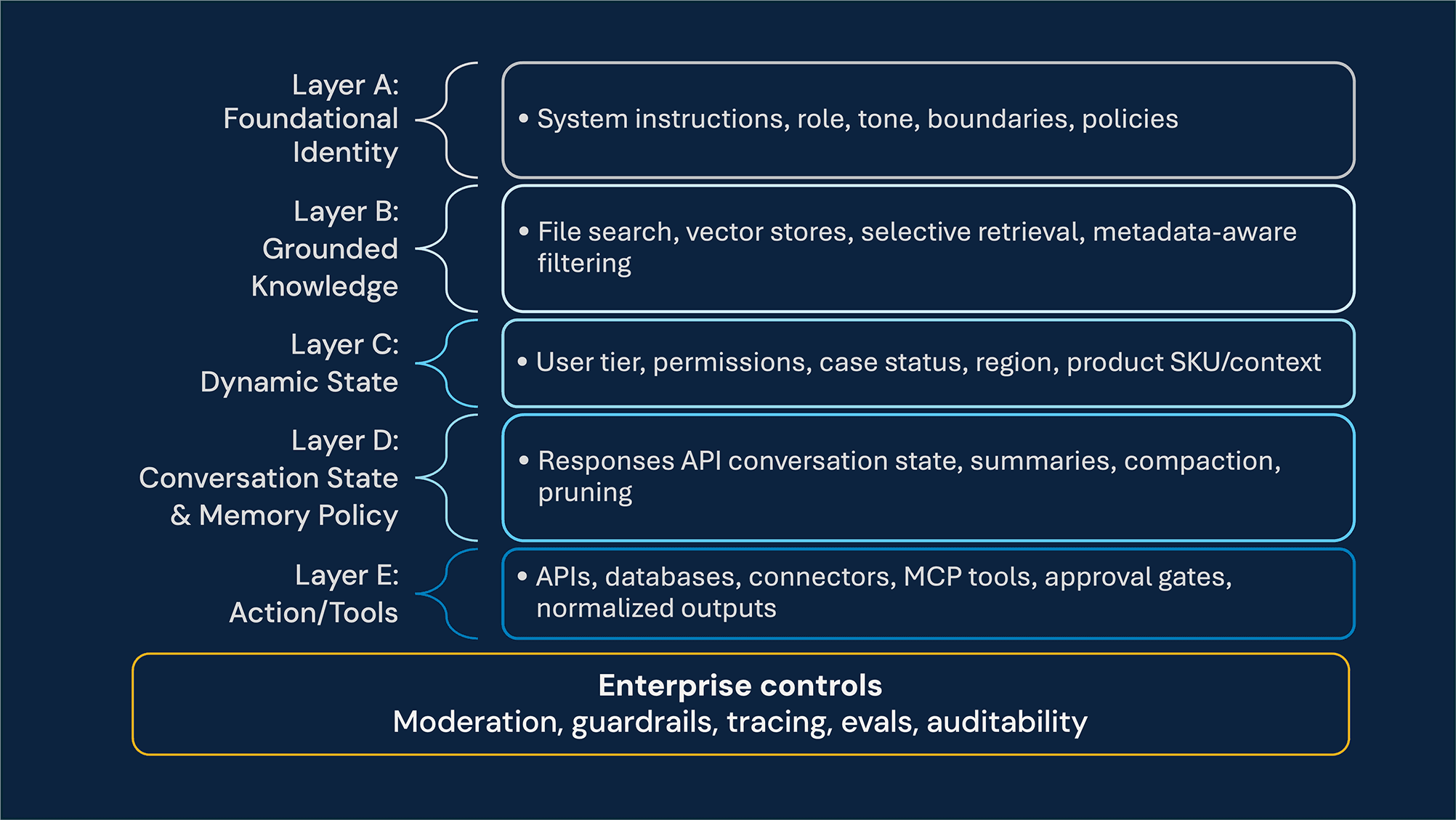
Layer A: Foundational Identity (System Instructions) – This layer defines the agent’s core identity, tone, boundaries, and firm rules. It is the baseline that keeps behavior consistent across tasks and channels.
Layer B: Grounded Knowledge (RAG Layer) – This layer serves as the truth engine. Using OpenAI Vector Stores, selective retrieval, and metadata-aware filtering, we expose only the documents relevant to the user’s product, region, and task. This improves answer quality while also reducing the risk of surfacing stale, incompatible, or unnecessary information in context.
Layer C: Dynamic State (Environmental Layer) – This layer captures the live conditions around the interaction, including the user’s role, permissions, current task progress, and any runtime constraints that should shape the agent’s decisions
Layer D: Conversation State and Memory Policy – This layer manages active conversation state across turns using OpenAI’s server-managed conversation continuation in the Responses API (for example, previous_response_id), or Agents SDK sessions when SDK-managed memory is the better fit. It also defines the policy for what should be retained, compacted, summarized, or pruned over time. If the use case requires durable memory beyond the active interaction, that memory should live in a separate enterprise store rather than be conflated with transient conversation state.
Layer E: Action (The Tool Layer) – This layer turns the LLM into an active problem-solver that invokes APIs, scripts, connectors, databases, or MCP-based integrations when needed. “Tool Hygiene” includes least-privilege tool access, approval gates for sensitive operations, and careful trimming or normalizing of bulky tool outputs before they are passed back into the OpenAI Responses API session or any downstream memory layer.
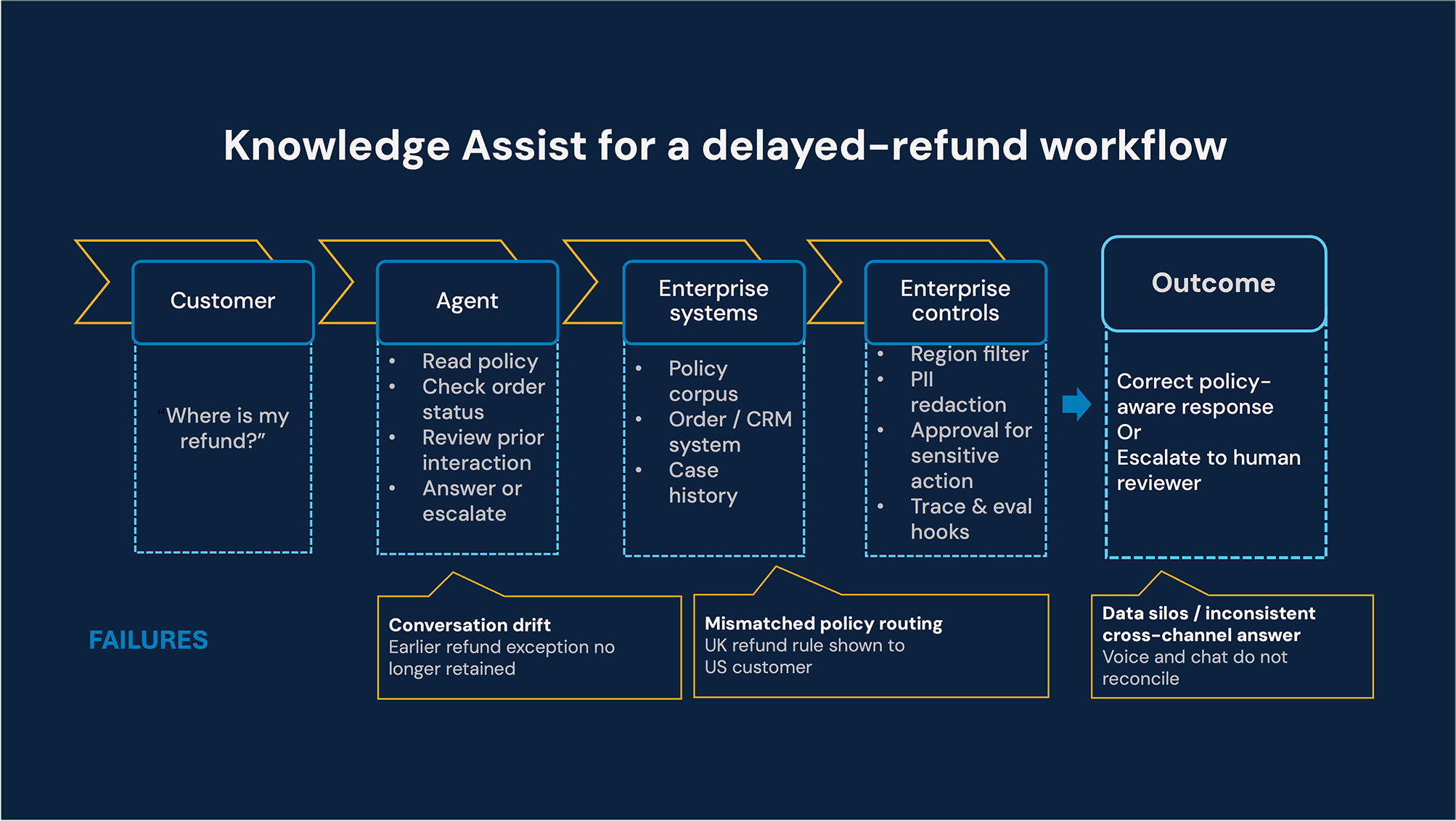
Deep dive use case: Global customer support knowledge assist
Global enterprises operate customer support across multiple regions, product lines, and millions of monthly interactions. Support agents struggle not because knowledge doesn’t exist but because the right context is not available at the right moment.
Consider a customer asking about a delayed refund. The answer may depend on several sources at once: the policy that applies to that market, the order system that shows the payment method and status, and the record of prior interactions. If those inputs are not brought together in real time, support agents are left to guess, over-explain, or put the customer on hold.
Typical failures include:
Mismatched policy routing: This occurs when documents are over-retrieved, causing an agent to mistakenly offer a UK refund policy to a US customer.
Conversation drift: This happens when hallucinated answers arise from a long history of previous chat turns.
Data silos: Here, inconsistent responses occur across voice and chat channels due to fragmented memory.
The goal is to build a Knowledge Assist agent that is accurate, secure, and improves constantly through evaluation.
In practice, such agents can be orchestrated using the OpenAI’s newer agent stack: the Responses API can manage multi-turn interactions and carry forward conversation state; file search and vector stores can ground answers in the relevant policy corpus; Agents SDK sessions can handle memory management across longer support flows; and tracing, guardrails, and evals can help teams monitor behavior, enforce boundaries, and improve performance over time.
How to operationalize the five-layer context architecture
The strategic frame above explains why context engineering matters; the sections that follow focus on how to implement it using OpenAI-native patterns inside a real enterprise workflow. This is also where the executive case translates into an engineering discipline: each layer becomes an explicit operating boundary that can be tested, governed, and improved.
To make the architecture production-ready, each layer must be implemented with discipline using the right OpenAI-native patterns.
Layer A: Foundational identity with system instructions & prompt optimizer
This layer defines the baseline behavior of the Knowledge Assistant: its role, boundaries, escalation rules, and evidence standards.
Defining system instructions for OpenAI
We establish a “Reasoning-First” persona for the agent. Before giving a customer a final response, the agent is required to describe its steps (Chain-of-Thought) using GPT-5.4 Thinking model capabilities. This guarantees that it doesn’t respond without first confirming internal knowledge.
Prompt optimizer for static context
Prompts from static systems are fragile. Fractal treats production failure transcripts as the signal for improvement. With OpenAI's Prompt Optimizer, we tackle this issue. We run multiple optimization cycles that use human-annotated datasets, including grader results, Good/Bad ratings, and failure cases. This process leads to more reliable and verifiable outputs that meet our behavioral needs by creating clearer instructions with specific guidelines, such as "Always cite the specific manual section used." Additionally, for more demanding tasks, reasoning effort can be tuned in GPT-5.4, but only after the core prompt and verification loop are stable.
Layer B: Grounded knowledge with vector stores and latest embeddings
This layer gives the agent access to the factual material it needs without flooding the context window.
Selective Retrieval over Bulk Injection
Instead of stuffing large volumes of documentation into the prompt, we use OpenAI Vector Stores paired with text-embedding-3-large and file search to retrieve only the passages relevant to the task at hand. This allows the agent to search across millions of documents and retrieve only the top-K relevant “snippets.”
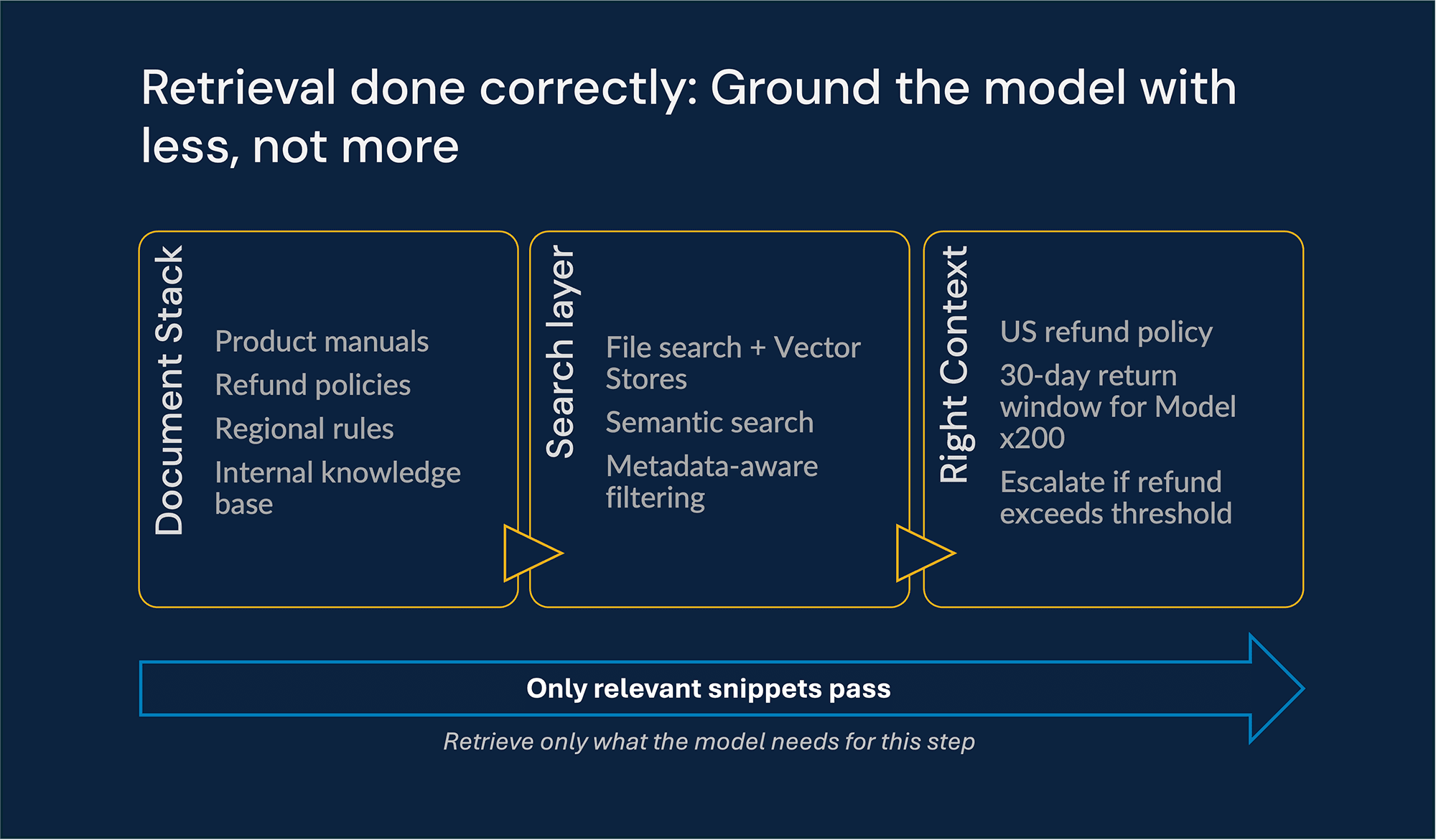
Metadata-aware filtering
We apply query-time filtering to ensure the agent only “sees” content relevant to the customer’s product SKU and region. This prevents the model from being distracted by irrelevant documents that might otherwise rank high in a generic vector search.
Retrieval as an accuracy + safety control
Selective retrieval is not just an optimization technique; it is a safety boundary. By constraining the information surfaced to the model, we reduce hallucinations, avoid exposure to internal‑only or outdated content, and prevent the agent from mixing incompatible policies or systems. Minimizing irrelevant context directly improves both answer quality and risk posture.
When enterprise data spans multiple internal systems, connectors, and remote MCP servers can provide controlled access to those sources through the OpenAI Responses API. That makes it possible to expose the right tools and data paths to the agent without hard-coding connection logic into prompts. Approval flows, tool filtering, and access controls then become part of the governance model.
Layer C: Dynamic state
Customer support is inherently contextual. We inject Dynamic State as structured metadata into the active conversation state on every turn - either directly with a Responses API call or through the orchestration layer when Agents SDK sessions are the better fit. Typical fields include:
User tier
Product ownership, version, or SKU
Regional or regulatory context
Case status, channel, or escalation state
By isolating this layer, we prevent state contamination. When the user switches from asking about a server to a laptop, the Dynamic State is updated instantly, shifting the agent’s reasoning without it being “stuck” on the previous topic.
Layer D: Conversation state and compaction with the OpenAI responses API
We move from replaying raw message arrays on every turn to using OpenAI’s server-managed conversation continuation in the Responses API for multi-turn flows, with the OpenAI Agents SDK used when SDK-managed sessions and orchestration are the better fit.
We use GPT-5.4’s native response compaction for long-running troubleshooting flows. When a conversation crosses a token threshold, older turns can be replaced by an encrypted, opaque compaction artifact that carries forward task-relevant state for subsequent turns. This reduces token load and compute overhead while preserving continuity.
To manage working memory across different task types, we use two complementary strategies
Context trimming
Used for quick Q&A to keep the last N turns for immediate context. We utilize “Fractal” logic here to define protected fields (IDs, policy constraints, approvals) that must never be pruned. Fractal also caps and normalizes tool outputs before they enter memory, a process we call “Tool Hygiene.”
Structured summarization
Used for complex technical support to compress past troubleshooting steps into a structured “State of the Case” report. This replaces aging history with a compact summary while keeping the latest turns verbatim. Fractal enforces a Structured Summary Schema (Environment, Issue, Decisions, Constraints, Next Steps) and includes Contradiction Checks to quarantine untrusted or noisy RAG data.
Layer E: Action - Tools without context exhaust
The agent uses tools to resolve cases, check ticket status, and trigger downstream actions such as dispatching an on-site technician.
Tool hygiene
Raw API responses from CRM,ERP and support systems often contain thousands of tokens of redundant JSON. Fractal applies tool hygiene so that the agent receives the semantic conclusion rather than the raw trace. – For example, instead of passing a large JSON payload back into context, the system can pass a compact result such as: “Ticket #123 is pending because shipping information is missing.”
Tool hygiene includes least-privilege permissions, approval gates for sensitive actions, output normalization, redaction where necessary, and strict boundaries around what tool artifacts are allowed to enter memory. This keeps the context window useful for reasoning rather than crowded with machine residue.
Safety, compliance, and trust
Safety controls need to operate at multiple layers. All user inputs and model outputs are screened with OpenAI’s Moderation models, then passed through application-level guardrails using Eval tooling, such as promptfoo, to catch jailbreaks and high-risk content, like payment card details. If a guardrail detects a safety violation like a jailbreak attempt or sensitive data, it immediately blocks the interaction before expensive tools or models run, reducing risk and wasted compute. Before transcripts hit long-term memory, we detect and redact PII so the agent retains problem context without storing identifiers like government IDs or account numbers. These controls support our secure data‑handling practices.
Built-in guardrails
OpenAI Moderation API filters all inputs and outputs
AgentKit Guardrails detect jailbreak attempts and sensitive data exposure
Privacy and regulatory compliance
Before any interaction enters long-term memory:
Personally Identifiable Information (PII) is redacted
Only task-relevant facts are retained
This ensures compliance with GDPR, HIPAA, and enterprise data governance standards, without sacrificing continuity.
Multimodality: Images, documents, and voice
Modern support workflows are not text-only. Customers share product photos, screenshots, PDFs, and voice interactions, and the agent needs to use those inputs without overwhelming its working context.
We call this pattern Vision to Structure. Using GPT-5.4’s vision features, the agent can “see” a photo of a broken part. Instead of storing the high-resolution image in the context window, the agent extracts the important details: “Broken fan blade on Model X-200.” Only this text fact remains in the context window, while the image is removed after processing.
The same principle applies to documents and transcripts: convert rich inputs into the smallest reliable representation that still supports the next reasoning step.
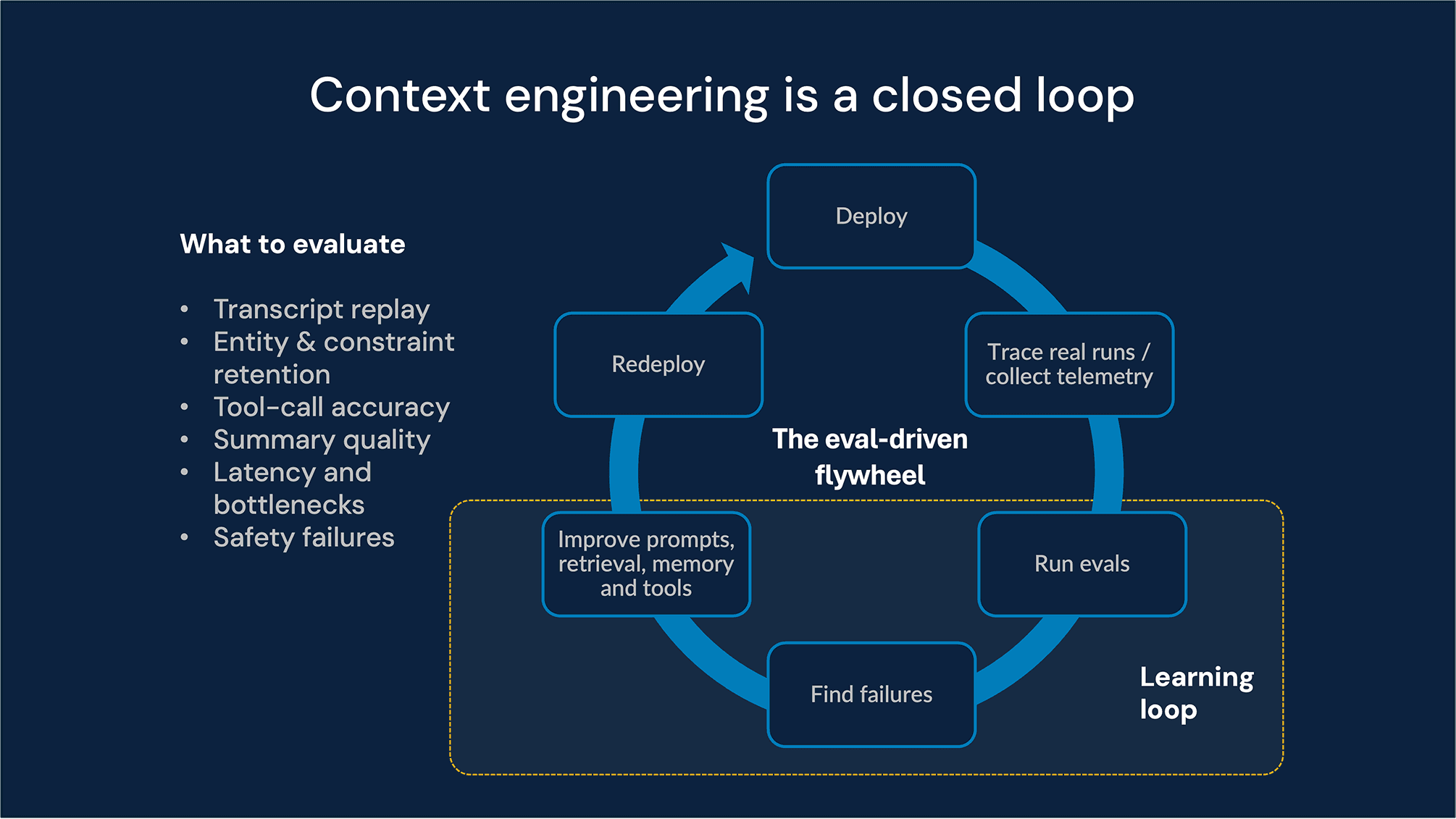
Eval-driven context engineering: The enterprise feedback loop
In an enterprise setting, context engineering is a continuous improvement cycle. To move towards a mission-critical deployment, we follow a strict Eval-Driven Development (EDD) model. To move from prototype to mission-critical deployment, teams need to measure how context policies perform under real conditions, track regressions over time, and connect technical quality to business outcomes.
We not only design the context but also measure its effectiveness, using detailed telemetry to link technical performance to your business metrics.
Our five-pillar evaluation suite
Transcript replay
We treat every historical interaction not just as a log, but as a vital test case. By converting past conversations into JSONL Datasets, we can “replay” them through the OpenAI Evals API under different context policies.
Next-turn correctness: We specifically measure whether the agent can still provide the correct answer after its context has been pruned or summarized.
Policy variation: This allows us to test “what-if” scenarios, such as lowering token limits without risking the user experience in production.
Continuous improvement: These replays form a regression suite that ensures a new system prompt doesn’t accidentally break an edge-case conversation that previously worked.
Entity and constraint retention
In long-duration workflows, certain “anchors” like Ticket IDs, UUIDs, or specific error codes must never be discarded. To safeguard these, we implement automated audits using OpenAI’s String Check Graders and Structured output validation via deterministic Python-based graders.
We use the String Matcher to perform a binary check: “Is the Ticket ID from turn 1 still present in the context after the turn 10 summarization?”
By using a grader, we teams prevent the “Contextual Drift” where a model gradually loses grip on core constraints as new, less relevant information enters the conversation.
Tool-call accuracy
Context isn’t just about text; it’s about the accuracy of actions. A production agent has to choose the right tool, call it with the right arguments, and respect the right operational boundary. We monitor “Layer E” the execution layer, by integrating OpenAI Model Tracing, we audit the step-by-step reasoning path (the ‘Trace’), ensuring the agent didn’t just find an answer, but followed the correct organizational procedure to get there.
Summary quality via model-based grading
Summaries are one of the most powerful tools in context engineering, but they introduce their own failure mode: losing or distorting the facts that matter. That makes summary quality a first-class evaluation target.
For this layer, we use model-based graders alongside deterministic checks. Deterministic graders verify required fields and format. Model-based judges score the summary against criteria such as faithfulness, relevance, and concision. Strong evaluation models, such as GPT-5.4 or selected reasoning models, can be used here, depending on the cost and rigor required by the workflow.
To implement a high‑performance LLM‑as‑a‑Judge system with OpenAI, we use a Structured Evaluation Prompt and a carefully designed grader prompt that scores the rubric Faithfulness, Relevance, Conciseness and verifies the required output format.
These judge scores are not just static reports; they are fed directly back into the OpenAI Prompt Optimizer to perform deep contradiction checks, enforce strict format specifications, and ensure precise role alignment and safety guardrails.
Pressure-testing and token threshold monitoring
One of the most costly failure modes in long-running agent workflows is losing the constraints or identifiers required to complete a task correctly.. To reduce that risk, teams need to monitor the point at which growing context begins to hurt answer quality, tool accuracy, or latency.
At Fractal, we treat that as an operational discipline with three controls:
Token usage telemetry: We utilize the usage metadata from the OpenAI API responses to track pre- and post-operation context sizes. By monitoring Prompt Caching hits and misses, teams can detect when the context window is fluctuating or nearing its limit.
Tracing hooks (OpenTelemetry): Using the OpenAI Agents SDK and OpenTelemetry (OTEL), we log “Context Eviction” spans. This allows you to see exactly which previous turns of the conversation were dropped to make room for new input.
Eval-triggered alerts: If our automated String Matcher fails during a high-density session, it indicates a “Protected Anchor” (like a Ticket ID) has been pruned. This initiates an immediate, deeper audit or a “summarization retry” to restore the missing data.
Enterprise tradeoffs: Observability vs. privacy
As agents become stateful, enterprises must consciously balance debugging needs against retention and privacy constraints. More visibility (logs, traces, retained histories) improves reliability but increases governance obligations. Key tradeoffs include:
Observability vs. retention: High‑fidelity logs accelerate root-cause analysis but expand the data footprint.
Tracing vs. privacy posture: Step‑level tracing improves auditability yet may capture sensitive intermediate state unless controls are applied.
System state vs. Chat history: Keep long‑term rules and constraints in structured system metadata. Chat history should stay lightweight and disposable, so old turns can be safely pruned without losing important policies.
Managing these boundaries is core to responsible context engineering.
Combined with the evaluation suite above, these controls form a practical governance flywheel: observe live behaviour, evaluate against policy and business outcomes, refine prompts, retrieval, memory, and tool boundaries, and redeploy with tighter guardrails. That is how teams operationalize context engineering in production rather than treat it as a one-time prompt exercise.
Final thoughts: Build, test, iterate
Implementing context engineering is an ongoing journey. Start by clearly defining how each layer A-E will function in your system. Then build small: perhaps a simple end-to-end happy path through the layers for one example task. Use that to shake out integration issues. From there, gradually add complexity: more retrieval data, more memory to juggle, more tools, more evaluation criteria. After each addition, leverage Layer E methodologies (transcript replays, LLM-as-judge) to verify nothing broke and to measure improvements.
In the end, effective context engineering will make your AI agents far more robust, explainable, and scalable. Instead of a black-box model that might do anything, you’ll have an engineered system where each part has a purpose and a check. This is how you take AI “from prompts to production” reliably. In production, the winning pattern is a closed loop: instrument the context, evaluate it continuously, tighten the guardrails, and feed those learnings back into prompts, retrieval, memory, and tools.
Conclusion: Context is the product
In enterprise AI, context is not an implementation detail; it is the product.
By grounding agent design in OpenAI’s platform primitives (Responses API Sessions, Vector Stores, Moderation, Evals, and Agents SDK, where orchestration is needed) and applying Fractal’s disciplined context engineering, enterprises can move beyond fragile demos to resilient, trustworthy systems. The future of enterprise AI will be defined not by who has the largest model, but by who engineers context with the greatest precision.
Recent Blogs

