Personalizing language models with a two-stage fine tuning approach
By Abhishek Gautam and Swarna Jha
Large language models (LLM) have reshaped how organizations analyze text, summarize content, and reason across domains. Their broad training makes them powerful generalists. That generality can limit performance when the task depends on domain rules, internal vocabulary or company specific preferences.
Teams that jump straight to end user fine tuning often face high compute cost, sparse or noisy data, and models that do not perform well across related tasks.
A practical alternative is a structured path that first adapts a base model to a domain and then personalizes it for a company, business unit, or user group. This two-stage approach is designed to improve accuracy on real tasks, reduce costs, and create a modular system that teams can govern and reuse across the enterprise.
Why general models plateau in enterprise use
General purpose models learn from large collections of publicly available text. That training does not encode industry specific constraints, compliance rules, or internal style. When prompted with domain heavy inputs or company specific workflows, output quality often drops.
Directly fine-tuning only on end user data can overfit small datasets, inflate training costs, and yield inconsistent behavior. A layered strategy addresses these limits by first adapting the model to the domain and then personalizing it to the organization.
The two-stage framework: Domain adaptation and user personalization
Stage 1: Domain adaptation
Adapt the base model on curated domain data such as regulations, product taxonomies, service policies, and realistic tasks. The result is a domain-adapted model that understands terminology, constraints, and edge cases that matter in that field.
Stage 2: User personalization
Fine tune the domain model on organization specific data such as portfolios, catalogs, routing algorithms, internal tickets, and interaction logs. This aligns the model with the preferences and workflows of analysts, agents, and customers in context.
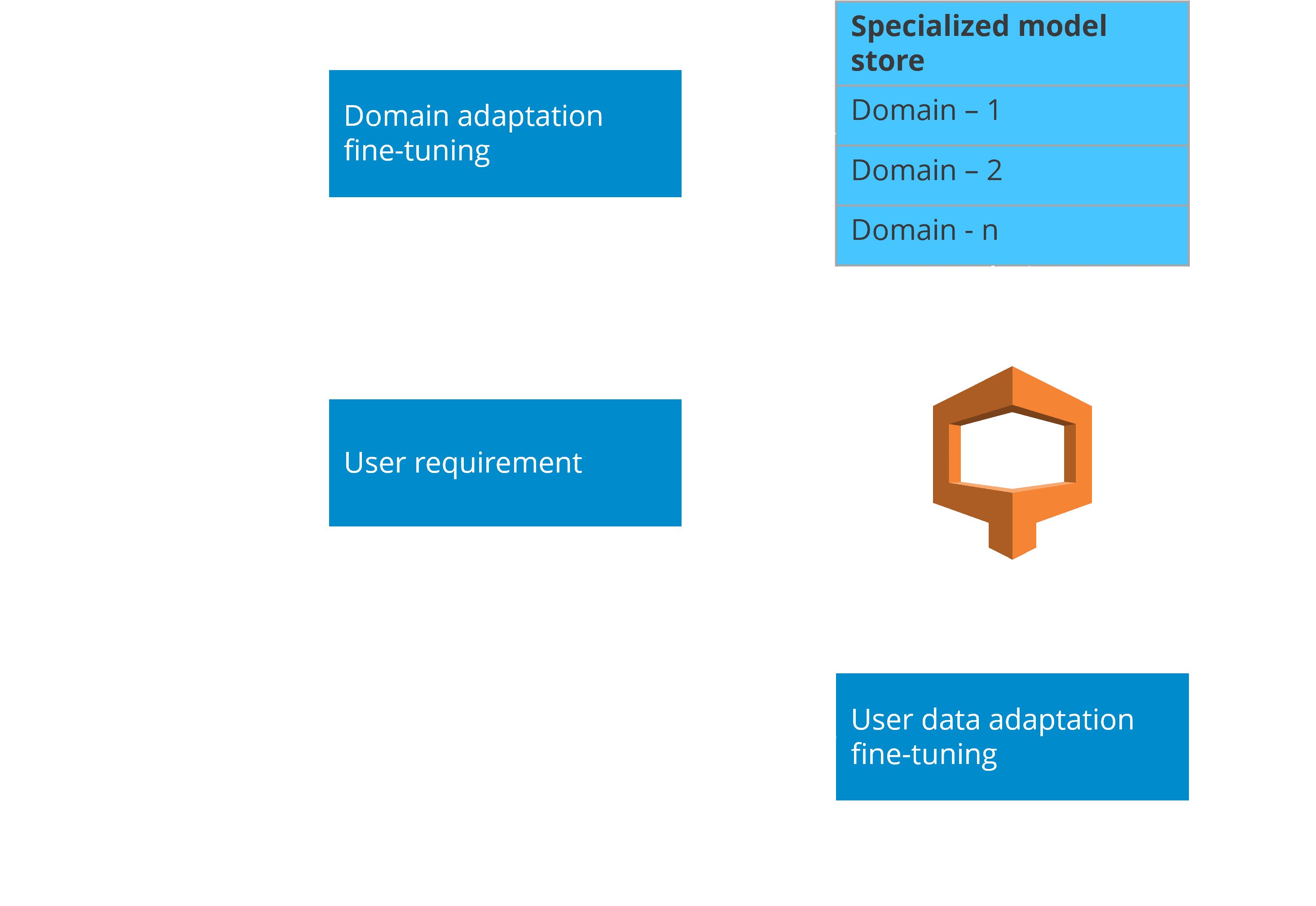
Exhibit: Two-stage fine-tuning process to personalize language models
The workflow of the two-stage fine tuning process (shown in the exhibit above) starts by adapting a base model to each domain to build a specialized model store. For a new requirement, the system selects the best domain model and fine tunes it with company data to deliver a client-specific model.
In many cases, a personalized model can outperform a domain model on organization tasks, and both can perform better than an untouched base model on the same tasks. To achieve these gains at scale, organizations must prioritize efficiency in how they design, train, and serve models.
Making personalization efficient and scalable
Efficiency starts with clear choices about how companies adapt, update, and serve models. The goal is to help reduce compute, shorten iteration cycles, and keep reliability high as adoption grows. To ensure efficiency and scalability, organizations can use the following techniques:
Parameter efficient fine tuning
Think of a large model as a production database. Full fine-tuning is like cloning the entire database for every application, which raises cost and complicates operations. Techniques such as LoRA (Low Rank Adaptation), QLoRA (Quantized Low Rank Adaptation), and adapter modules train only a small set of additional weights while the backbone stays frozen.
LoRA inserts low rank matrices inside transformer layers to cut the number of trainable parameters and memory required.
QLoRA combines these adapters with 4-bit quantization to fit large models on a single modern GPU while preserving quality.
Adapter modules add compact bottleneck layers that can be swapped per task without changing the base model.
Continual learning
As user data evolves, the personalized model must learn without forgetting prior skills. Replay buffers, regularization-based methods, and dynamic architecture updates are standard ways to mitigate catastrophic forgetting so performance remains stable over time.
Meta learning for cold starts
When organization data is scarce, few-shot learning algorithms such as MAML (Model Agnostic Meta Learning) train model initializations that adapt quickly to new tasks with a few examples. This approach reduces time to value during onboarding.
Right-sized infrastructure
An efficient setup relies on strong infrastructure. It includes GPU or TPU clusters for large-scale training. This uses distributed frameworks such as DeepSpeed or PyTorch Distributed to coordinate workloads, and optimized data pipelines that stream domain and user data.
To measure outcomes, teams can use standard metrics such as accuracy, F1, and BLEU (Bilingual Evaluation Understudy) when relevant, and pair them with task-level business KPIs. This combination ties model improvement to measurable outcomes.
Industry applications of the two-stage framework
Finance: A base model fine-tuned on regulations and market data can be adapted to a client portfolio for personalized investment advice. This can support analysis and recommendations that align with mandates and reporting standards.
Fashion and retail: A model trained on trend data, product taxonomies, and style rules can be personalized to merchandising calendars, brand voice, and regional inventory. This can improve curation, product storytelling, and localized content.
Logistics: A domain model trained on routing algorithms, service levels, and supply chain constraints can be personalized to fleet mix and historical exception patterns. Planners can gain schedules and recommendations that reflect real operating limits.
Technology: A model adapted to incident taxonomies and knowledge bases can be personalized with resolver notes and ticket histories. Suggestions can reflect escalation rules, runbooks, and toolchains already in place.
Healthcare: A model adapted to clinical terminologies and safety guardrails can be personalized with context from approved data sources. Care teams can receive summaries and suggestions that are relevant and consistent.
These scenarios show how domain adaptation and organizational personalization work together. The domain layer is reusable across teams and time. The personalization layer captures fast changing signals and preferences. This separation improves governance, lowers cost, and accelerates iteration while keeping outcomes tied to business goals.
Conclusion
Enterprises need models that understand the business and adapt to the way teams work. A two-stage fine tuning framework is designed to help deliver that result. Start with domain adaptation to set the right foundation. Add user personalization to align with real tasks and preferences. The approach can lead to higher accuracy, lower cost, and cleaner governance, with models that can evolve as the organization and data change.
For organizations that plan to operationalize this approach, Cogentiq LLM Studio from Fractal is a viable solution. It provides an integrated way to train, tune, evaluate, and deploy custom domain-aware and user-personalized models. It also supports end-to-end workflows with governance, cloud pipelines, and reusable adapters that map directly to the two-stage method.
Recent Blogs

