

Enhanced predictive power
Better model fit
Higher success rate
Improved accuracy
The challenge
Unlocking the power of unstructured data
Traditional preventive care relies heavily on structured data, often missing valuable insights hidden in unstructured sources like clinical notes, patient feedback, and medical transcripts. By leveraging AI-driven analysis, healthcare providers can unlock deeper patterns, improve early detection, and enhance patient outcomes.
Key challenges
Structured data overlooks key health indicators
Unstructured records remain untapped
Extracting insights is complex
Risk factors go unnoticed
The solution
AI-driven insights for smarter risk prediction
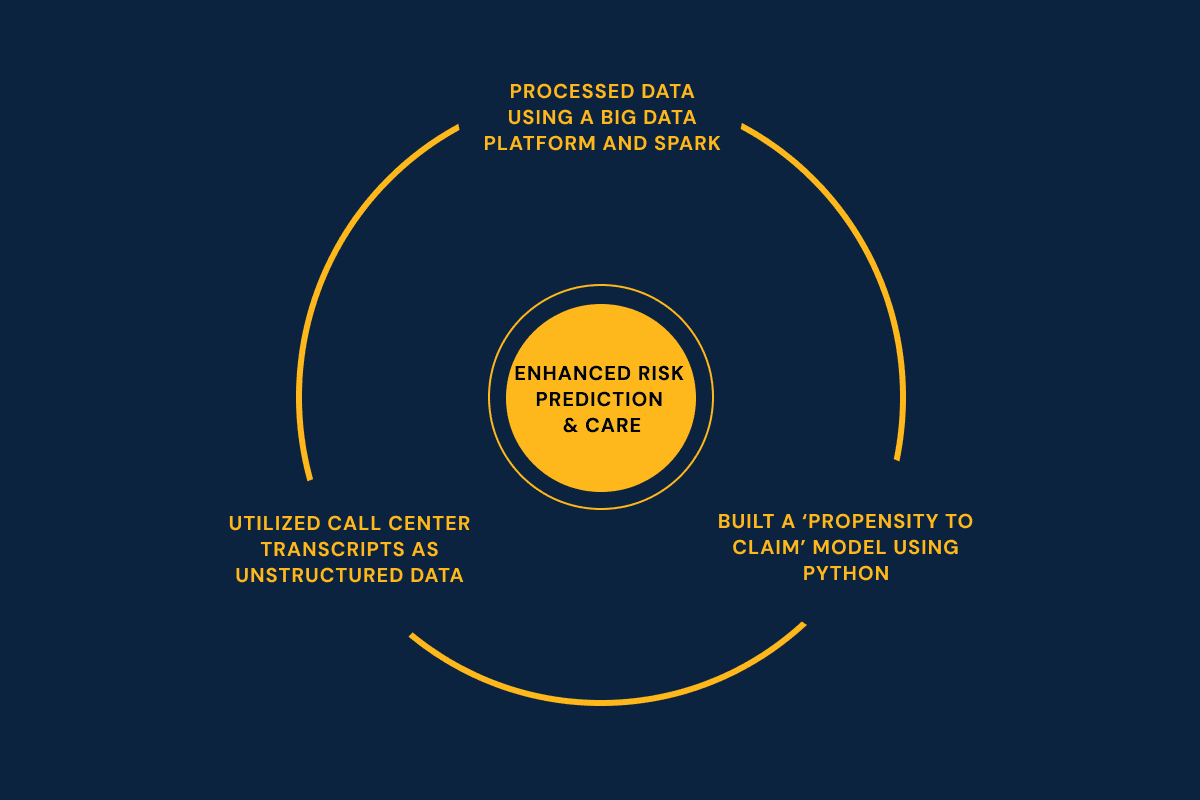
Harnessing unstructured data
Analyzed call transcripts
Used big data and Spark
Built AI propensity model
Boosting predictive accuracy
Merged data sources
Built an ensemble model
Improved risk prediction
Implementation approach
1
Data processing
Mined call data patterns
Applied analytics
Optimized big data
2
Model development
Built AI for claims
Improved accuracy
Merged data sources
3
Risk scoring and action
Scored member risk
Enabled proactive care
Prioritized high-risk cases
The impact
Enhanced predictive accuracy for proactive care
Stronger model performance
KS statistic up 11% (35% → 46%)
Improved model accuracy
Data-driven insights
Better predictions
Success rate +12% (63% → 75%)
Concordance +10% (66% → 76%)
Improved risk assessment
Higher accuracy
Accuracy +4% (68% → 72%)
Enhanced risk scoring
Improved early detection
Looking ahead
Advancing AI insights
Expand AI capabilities for deeper analysis
Real-time risk detection
Enhance early detection using live data
Scalable healthcare solutions
Broaden impact through wider implementation

