Disruption has given a new dimension to the data drift challenge. Businesses grappled with changing consumer behaviors, leading to changing data patterns. How can we architect for change, manage data drift and even harness its power to accelerate digital transformation for your business?
Data drift is the unexpected changes in the data pattern, data structure, and semantics where the data fed into the model differs from the initial information.
The past 24 months of disruption have given a new dimension to the data drift challenge. Businesses grappled with changing consumer behaviors, leading to changing data patterns that could disrupt complete processes.
However, the question is, how can we architect for change, manage data drift and even harness its power to accelerate digital transformation for your business?
Detecting data drift
There are multiple ways to detect data drift. One of the approaches is using statistical tests that compare the distribution of baseline data to the live or production data. If we see there is a significant difference between the two distributions, then a drift has occurred.
Data drift detection can happen due to three broad things. There could be an observation gap, the freshness or relevance of data in the current time and the quality of data.

Figure 1: Data drift detection
Observability
Data can be static or dynamic, however irrespective of their nature, it is subject to variations. What differs is the intensity of these variations. Businesses should start with data observability early to understand and spot these changes.
Observability permits teams to interpret and explain unexpected behavior and effectively and proactively manage data. Even though drift prevention may not be completely possible, it can be managed to a large extent.
At Fractal, we capture all types of drift but covariate shift is the most prevalent and widely used. This is mainly done at the feature store level to anticipate drift by comparing the distribution of representative data sets. With the right observability strategy, translates to higher reliability, improved consumer experience and scaled productivity.
Freshness Check
With consumer behavior changing dynamically and rapidly, model performance degrades over time. Businesses must regularly check the freshness and data volume and monitor changes in the data schema. If there are any changes in the schema, it can lead to a potential data drift.
There are few models that can last for a long time, without any update, like computer vision or language models. Model quality metric is the ultimate measure and it can be accuracy, mean error rate or even downstream business KPIs.
Data Quality
At certain times, data fed into the serving model may be skewed or there may be distribution changes compared to the training data. Hence, we can say, that wrong data is a data quality issue. Data that is incomplete, incorrect or full of duplicates can lead to data drifts.
The main concern of data quality is if the data is ‘right’ or ‘wrong.’ A few common sources of data quality issues include:
Incorrect data entry
Quality control failed to remove data quality issues
Duplicate data records created
Data is not used or interpreted correctly
All available data about an object was not integrated
Data is too old to be useful in the current context
It is critical to have quality assurance for features from both ethical aspects and from anticipating the drift probability.
Challenges faced
The industry has numerous tools, and a business has different teams. These teams use different tools to handle each component, making it difficult to keep tight integration among the data. Moreover, a hundred tools are doing the same work, and there is no clear benchmarking yet. Organizations tend to choose tools by not understanding the actual requirement. This makes things complicated.
How automation can help
The automation journey has already started. However, adoption is where businesses are facing challenges, both from technical and operational sides. Cloud providers are moving towards automation. However, 100% automation may not be possible because the more flexibility we try to bring in through automation, the more complex the engineering can get.
It is important to understand how much flexibility desirable vis-a-vis the system’s complexity is. Hence, understanding the requirement very well is the first step. It will help us estimate how much to go ahead with.
If we overcomplicate the ecosystem, it becomes difficult to manage. The art is to keep things simple and still deliver value
So, there must be a balance between flexibility and complexity. Even if businesses achieve 70 to 80% automation, that would reduce repetitive work, and ensure data quality and data monitoring. To drive results with data drift automation, we need these five pillars of AI engineering or machine learning operations in place.
5 Pillars of AI and engineering:
Solid Data curation layer (Data lake, Data warehouse)
Feature Store and Feature QA
Model training, Management
CI/CD
Monitoring
How can we help
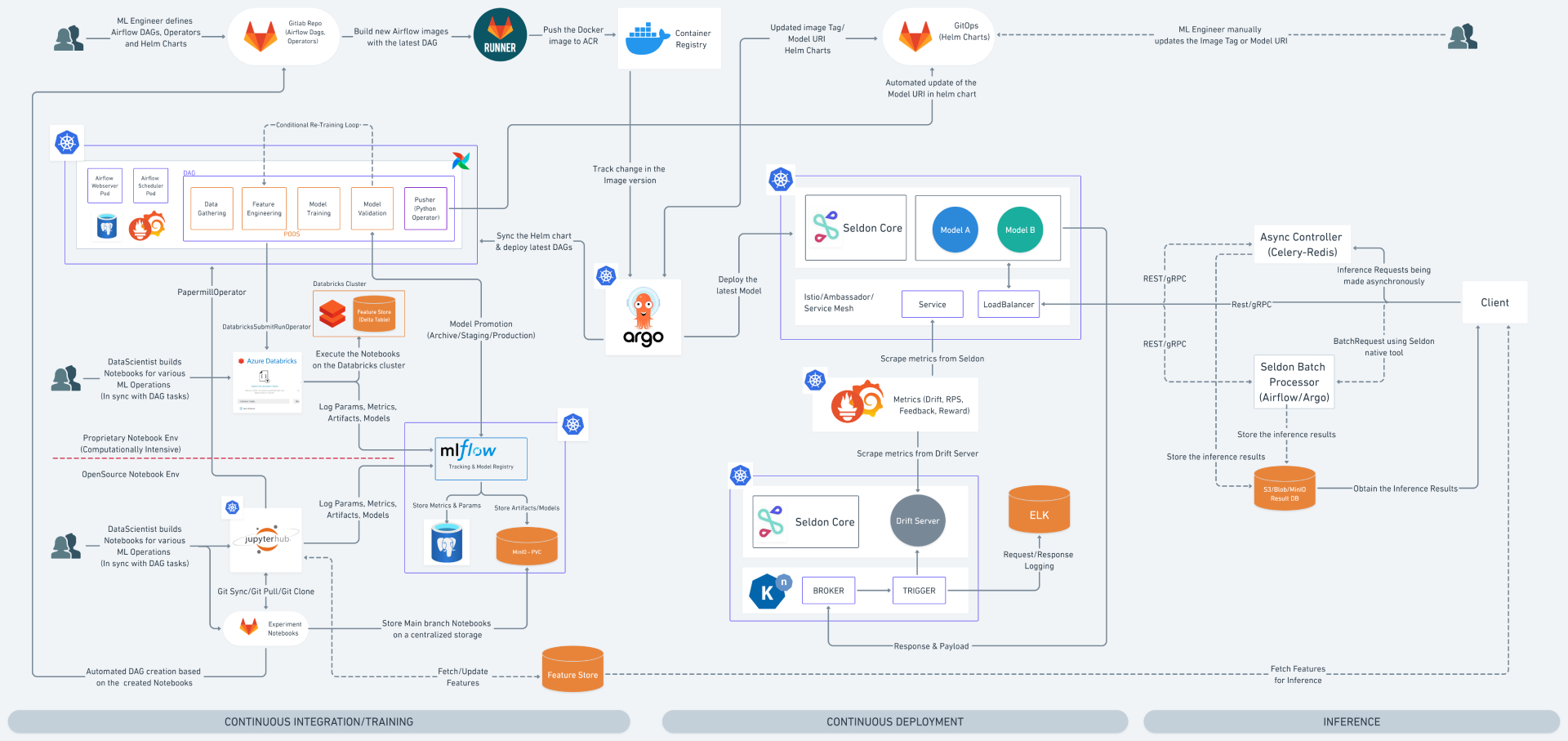
At Fractal, a lot of importance is given to monitoring and observability. It is not only limited to the model but the entire machine learning lifecycle. Currently, we are implementing a monitoring ecosystem in two projects and have created complete E2E ecosystem of ML lifecycle and monitoring as part of the internal initiative of the CoE.
We used all open-source tech stacks and entirely on Kubernetes. Our goal is to move towards CNCF and use all SOTA tools with good community support.
Useful considerations
Data scientists develop features and patterns by transforming raw data into meaningful ones. For flexibility, they resort to feature engineering. However, when data is vast and complex, they feel it is best to automate with easy-to-adapt designs. The mantra is not to complicate and find solutions where integration is seamless.

Conclusion
Most businesses are adopting machine learning for key business decisions. However, the limited data quality and lack of ability to evaluate the quality of data, creates trust issues. In the upcoming time, there will be a continuous transition of technology with data automation really taking off. But for all that to happen, the quality of data, simplicity and flexibility of solutions, and easy adaptability are key.
What is required is the collaborative work of data scientist and data engineers, expanding their boundaries and entering into each other’s domain to improve quality and model implementation. The key focus will remain productionization of the model with regular maintenance.





