Democratizing language models: From one-size-fits-all to fit for purpose
Enterprise leaders want language models that answer with precision and speed. However, only a fraction of corporate data feeds today’s models, and generic systems often struggle with specialized jargon or regulatory nuances.
The key challenge is clear. Organizations need language models that understand their domain, reason with their own data, and run efficiently at scale.
Limitations of generic language models
Generic models learn from broad web data, so they rarely encounter specialized vocabulary, citation standards, and privacy constraints that govern enterprise data.
These models may also substitute plausible sounding but incorrect details, resulting in compliance risks. Additionally, the billions of parameters that give them general fluency also raise serving costs, energy use, and latency, making it difficult to embed them in real-time workflows.
An ideal way forward requires systematic context enrichment and disciplined life-cycle management that turns a generic model into a fit-for-purpose engine.
How enterprises are tweaking language models to suit their needs
AI native organizations view accuracy, compliance, and speed as non-negotiable attributes. This is why they’re looking for practical ways to align language models with their own data and workflows. That has led many organizations to a focused set of adaptation strategies that turn general purpose language models into domain experts. Here are a few proven approaches:
Parameter Efficient Fine Tuning (PEFT): In this approach, the process begins with the base model, but updates only small, targeted weight blocks on carefully labeled task data. This light touch adapts the model to new tasks with low compute cost, short training time, and modest data needs while keeping latency low.
Retrieval Augmented Fine Tuning (RAFT): This technique refines a model and then attaches an external retrieval system that feeds relevant documents to the model at runtime. The extra context grounds answers in fresh knowledge and lifts both answer relevance and explainability to high levels while preserving strong domain adaptation.
Continued Pretraining (CPT): In this technique, a base language model is trained on a large unlabeled domain corpus until the network learns the field’s critical vocabulary, nuances, and patterns. The outcome is high answer relevance, low inference latency, and strong domain adaptation once the model is in production.
Enterprises need a complete solution to democratize language models
Most cloud platforms and third-party service providers in this space only offer fragments of the language model customization pipeline. Teams then need to stitch together compute orchestration, data preparation, tuning and reasoning jobs, retrieval layers, evaluation, and monitoring.
This often inflates cost, delays pilots, and leaves critical gaps in governance. Disparate services also create region limits and manual integrations that block rapid iteration.
The Cogentiq LLM Studio from Fractal addresses these challenges with a cloud first pipeline that automates continued pretraining, parameter efficient fine tuning, and retrieval augmented tuning in one interface. It also provides observability, cost controls, and scalable deployment, letting enterprises deliver domain adapted models on demand using LLMOps practices.
Building custom language models on-demand with NVIDIA
To put this into practice, Cogentiq LLM Studio runs on a reference stack built with NVIDIA software and infrastructure.
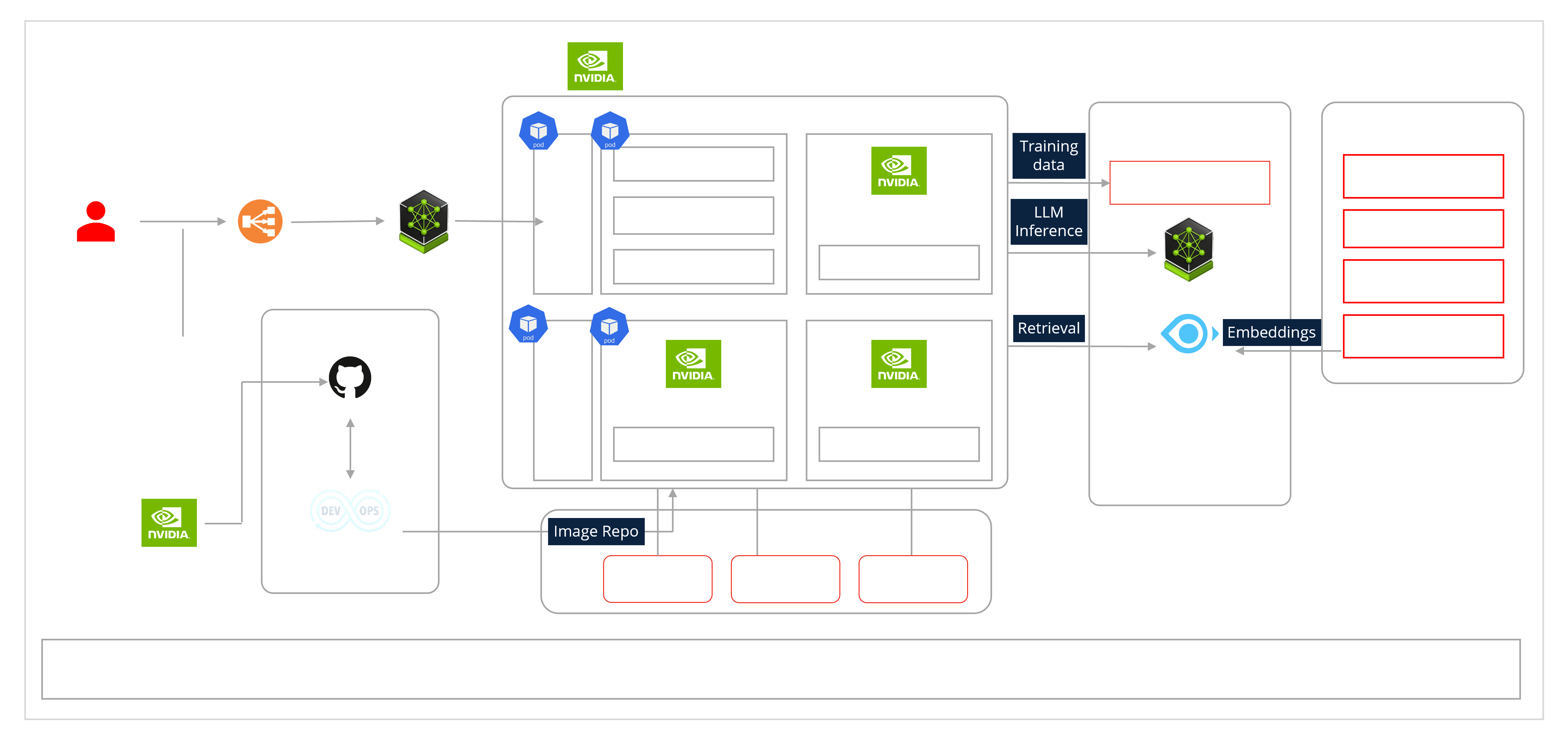
Exhibit: Reference architecture of Cogentiq LLM Studio, powered by NVIDIA
The stack spans data curation, continued pretraining, alignment, safe deployment, and retrieval so teams do not have to stitch tools together. It turns domain data into fit-for-purpose models that can be deployed at scale with clear governance. Here’s how it works:
The pipeline begins by curating and generating clean, domain specific datasets with NVIDIA NeMo Curator, which handles loading, cleaning, filtering, and deduplication.
A base LLM is then adapted through continued pretraining and aligned with supervised fine-tuning, Direct Preference Optimization (DPO), or Reinforcement Learning from Human Feedback (RLHF) using the NeMo framework and NeMo-Aligner.
The tuned model is packaged and served as a NIM inference microservice on NVIDIA accelerated infrastructure, while the GPU Operator manages drivers and runtimes across Kubernetes clusters.
NeMo Guardrails applies safety and policy controls between the application and the model to enforce content moderation and governance.
A vector database such as Milvus indexes embeddings so the application can retrieve relevant context at runtime and keep answers grounded in enterprise context.
Conclusion
Enterprises achieve meaningful outcomes from large language models when these systems are built to represent their domain knowledge, data, and decision logic accurately. This requires a disciplined process that connects data preparation, model tuning, infrastructure optimization, and governance into a single workflow.
The Cogentiq LLM Studio from Fractal, powered by NVIDIA, provides this structure through automated pretraining, fine-tuning, evaluation, and deployment within one platform. It enables organizations to maintain performance, control costs, and ensure compliance while scaling model usage across the organization.
Recent Blogs

