/
Blogs
/
Designing Enterprise GenAI Pipelines: From RAG Chatbots to Real-Time Document Processing Systems
A practitioner’s journey into GenAI pipelines
From conversational RAG to real-time document processing systems
Introduction: Moving beyond the chatbot narrative
Generative AI (GenAI) is often introduced to enterprise leaders through the lens of chatbots, and Retrieval-Augmented Generation (RAG) is typically positioned as the mechanism that improves chatbot accuracy by grounding responses in external knowledge.
That framing is helpful, but incomplete.
For CXOs evaluating enterprise AI strategy, the real opportunity lies beyond conversational interfaces. In practice, many high-value GenAI systems:
Process documents automatically as they arrive
Extract structured intelligence from complex files
Trigger downstream workflows
Support operational and clinical decision-making
Improve compliance, governance, and speed to action
These systems may use classic RAG architectures, but many do not. Some rely on document-scoped grounding. Others require strict schema-constrained generation. Some need vector databases; others explicitly should not use them.
The architectural truth is this:
GenAI pipeline design is not about adopting RAG.
It is about aligning input characteristics with output requirements.
This article walks through four enterprise GenAI pipeline scenarios, from conversational knowledge assistants to real-time claims processing, and explains how architectural choices emerge from first principles.
The two questions that shape every GenAI pipeline
When designing enterprise-grade GenAI systems, I start with two fundamental questions:
What does the input data look like?
What does the system need to produce?
Everything else, retrieval strategy, vector databases, orchestration patterns, validation frameworks, LLM agent usage, flows from these two anchors.
Factors determining the pipeline architecture
Input characteristics
Documents vs structured tables
Single file vs large knowledge corpus
Scanned PDFs vs digital native text
Layout-heavy vs narrative content
Event-driven (real-time) vs batch ingestion
Static archive vs continuously growing repository
Output requirements
Free-form text vs structured JSON
Schema-bound records vs narrative summaries
Citations required vs contextual accuracy sufficient
Human-in-the-loop vs fully automated workflows
Compliance-grade traceability vs productivity enhancement
When input and output are clearly defined, architectural decisions around:
Retrieval-Augmented Generation (RAG)
Vector databases
Metadata indexing
LLM agents
Orchestration frameworks
Validation and guardrails
become obvious rather than experimental.
Basic GenAI pipeline components
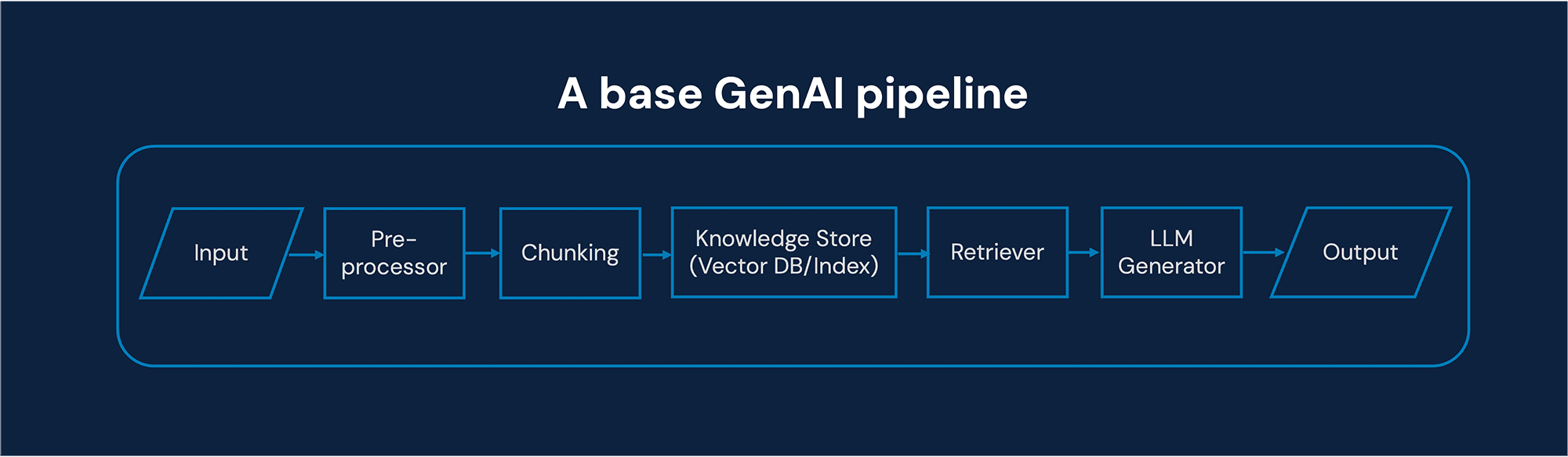
Before diving into use cases, let’s establish a common architectural vocabulary.
Every GenAI pipeline, regardless of complexity, typically contains these logical components:
Ingestion layer
Captures incoming data (documents, tables, streams, APIs).
Pre-processing and parsing
OCR (for scanned PDFs)
Layout detection
Chunking strategies
Metadata extraction
Retrieval or grounding layer
Document-scoped context injection
Vector database retrieval
Hybrid keyword + semantic retrieval
Metadata-driven filtering
4. Generation layer (LLMs)
Free-text synthesis
Schema-constrained generation
Function calling
Agent orchestration
Validation and guardrails
JSON schema validation
Business rule enforcement
Hallucination detection
Confidence scoring
Integration layer
Database writes
Workflow triggers
Human review dashboards
Audit logging
In enterprise environments, a single logical stage may involve multiple models, retrievers, tools, or agents, depending on complexity and compliance needs.
GenAI pipelines – Four enterprise AI use case scenarios
Rather than deep domain walkthroughs, the goal here is architectural clarity. Each use case illustrates how requirements reshape the pipeline.
Scenario 1: Real-time claims processing system
Business Context
An insurance enterprise receives claims documents in varying formats. The system must:
Parse layout-heavy PDFs
Extract relevant claim information
Summarize case details
Map extracted data to the database schema
Trigger workflow actions
This is not a chatbot problem. It is an operational automation problem.
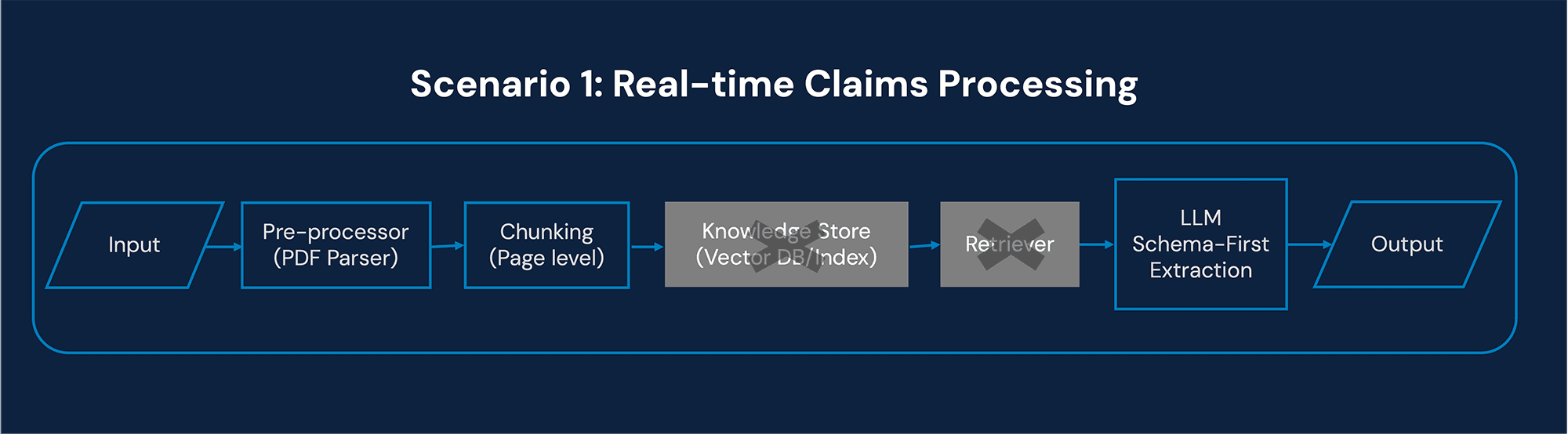
Input
Single, layout-heavy PDF
Event-driven ingestion (real-time processing)
Variable templates and formats
Output
Structured claim records
Schema-aligned database entries
Summary for internal review
Architectural Implications
Document-scoped retrieval
Context is limited to the single document being processed.
There is no need to retrieve from an external knowledge base.
No vector database
A vector DB adds unnecessary latency and complexity when processing a single event-driven document.
Constrained schema-first generation
The LLM must output strictly structured JSON aligned to the target database schema.
Multi-agent orchestration
Agent 1: Layout parsing & segmentation
Agent 2: Field extraction
Agent 3: Validation and normalization
Agent 4: Summary generation
Deterministic guardrails
Schema validation
Confidence thresholds
Business rule enforcement
For CXOs, this architecture highlights an important shift:
GenAI becomes a workflow engine, not a conversational interface.
Scenario 2: Enterprise data profiling and quality assessment system
Business Context
Organizations ingest large datasets into enterprise data platforms. Data quality issues delay analytics and AI programs. A GenAI system can:
Analyze metadata
Compute quality metrics
Generate narrative assessment reports
Flag anomalies
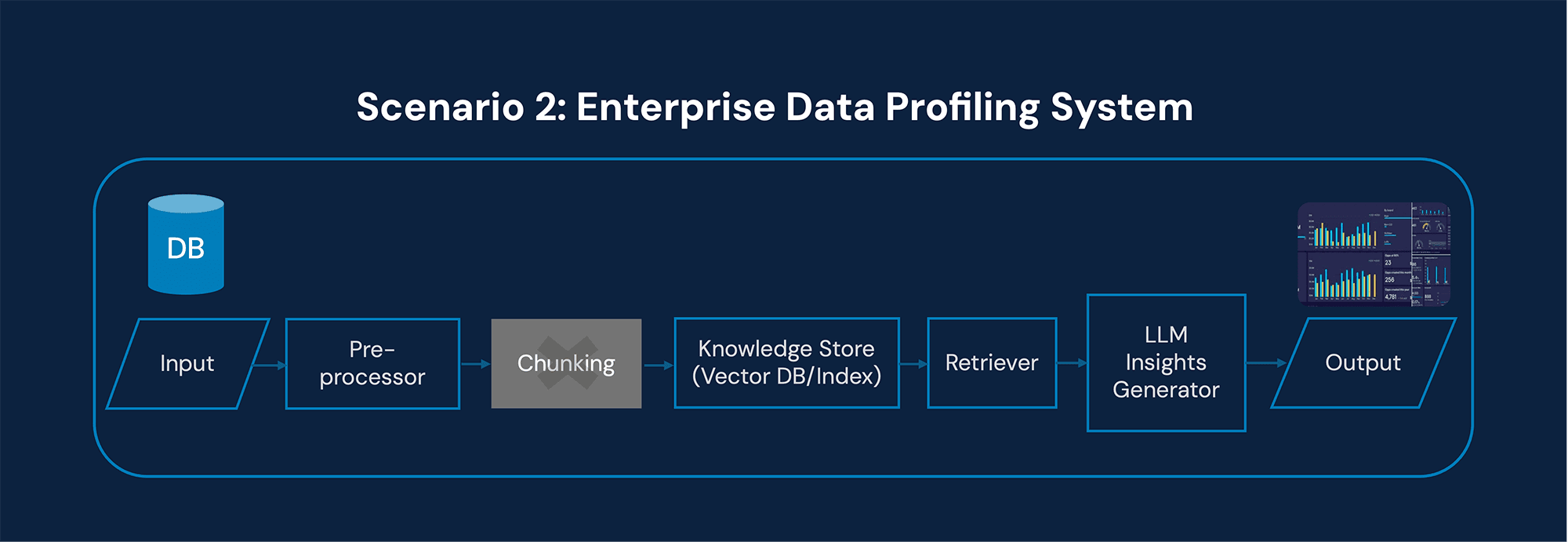
Input
Structured datasets
Metadata catalogs
Possibly associated documentation
Output
Quality assessment reports
Explanation of computed metrics
Structured quality indicators
Architectural implications
Metadata-driven retrieval
Retrieval is not a semantic text search.
The system queries metadata catalogs and data dictionaries.
Vector DB optional
A vector database may be used for documentation retrieval, but core profiling logic is deterministic.
Generator focuses on explanation
The LLM explains:
Null percentages
Distribution anomalies
Schema mismatches
Statistical irregularities
The heavy lifting is computational.
The LLM provides interpretability and executive-friendly insights.
For CXOs, this is strategic:
GenAI augments data governance, not just productivity.
Scenario 3: Clinical documents processing system
Business context
Healthcare organizations manage long, unstructured clinical documents:
Discharge summaries
Lab reports
Physician notes
Historical patient records
The objective is to extract clinically relevant information to support decision-making.

Input
Long, unstructured documents
Event-driven or batch ingestion
High compliance requirements
Output
Timeline summaries
Evidence-backed entity extraction
Structured clinical attributes
Architectural Implications
Document-scoped entity extraction
The context window must stay tightly grounded to the patient’s document set.
No vector DB (Typically)
Unless cross-patient research is needed, retrieval remains document-bound.
Strict schema-constrained generation
Outputs must adhere to:
Clinical entity schemas
ICD mappings
Time-sequenced event structures
High validation standards
Citation mapping to document segments
Confidence scores
Human-in-the-loop review
In regulated industries, GenAI is not about creativity.
It is about precision, traceability, and compliance-grade extraction.
Scenario 4: Business writing and knowledge assistant
Business context
A CXO or strategy team needs:
Executive summaries
Proposals
Board presentations
Knowledge-grounded content
The organization has a rich internal corpus of documents.
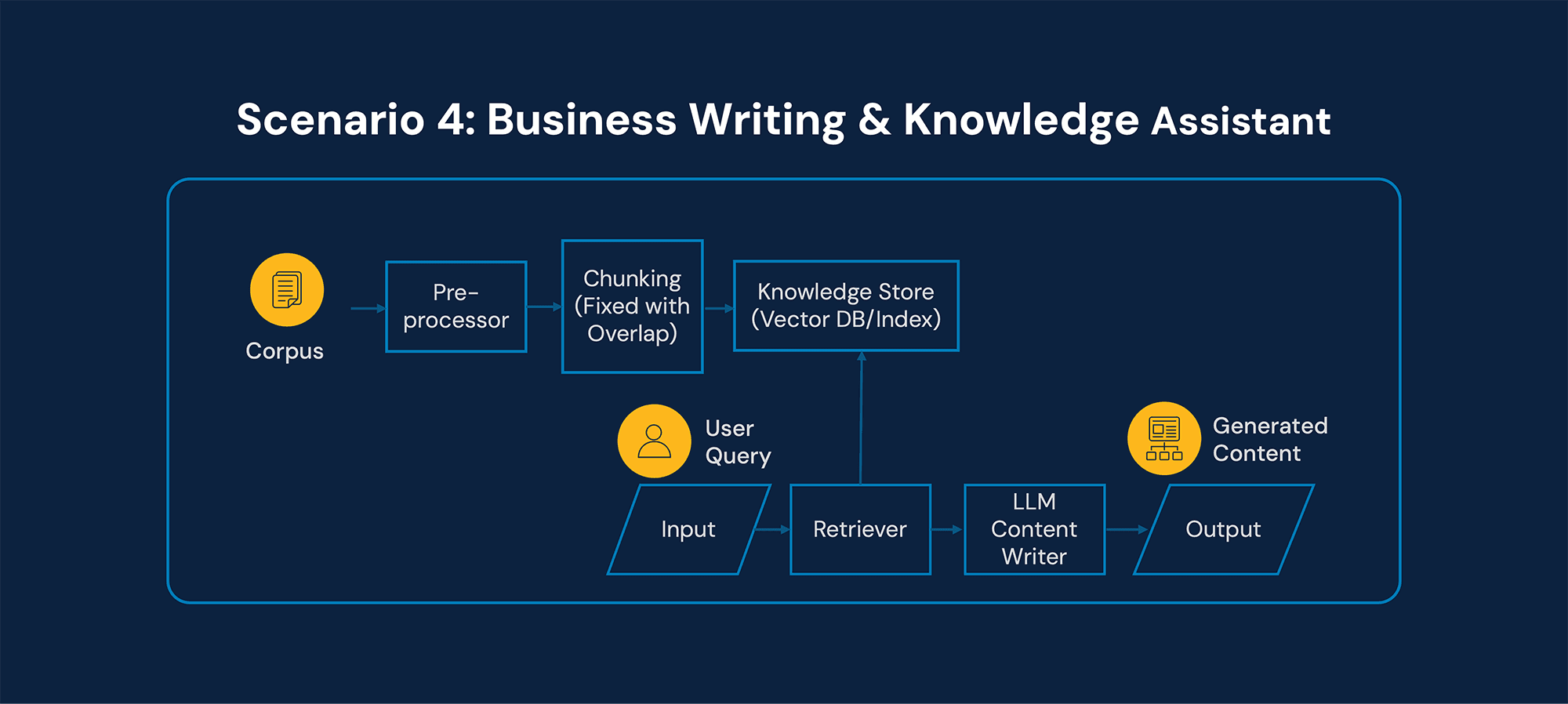
Input
Large corpus of unstructured documents
Continuously growing knowledge base
Output
Drafted content sections
Synthesized executive narratives
Citations grounded in prior documents
Architectural Implications
Classic Retrieval-Augmented Generation (RAG)
This is where RAG fits naturally.
Chunking Strategy is Critical
Semantic chunking
Reusable knowledge blocks
Context window optimization
Vector Database + Hybrid Retrieval
Semantic search
Keyword filtering
Metadata constraints
Generator Focuses on Synthesis & Style
The LLM:
Synthesizes across sources
Aligns tone to executive audience
Ensures narrative coherence
This is the canonical knowledge-assistant use case, where vector databases and hybrid retrieval unlock scale.
RAG is not a recipe; it’s an architectural choice
One of the most common mistakes in enterprise AI adoption is treating Retrieval-Augmented Generation as a mandatory template.
In reality:
Some systems require vector databases.
Some should avoid them.
Some rely on metadata indexing instead of semantic search.
Some demand strict schema-bound outputs.
Some prioritize synthesis and creativity.
The most effective GenAI systems are not the ones with the most components.
They are the ones shaped deliberately by:
Data characteristics
Latency requirements
Compliance constraints
Output structure
Business impact objectives
Strategic implications for CXOs
Align architecture to business value
Do not start with “Should we implement RAG?”
Start with “What operational problem are we solving?”
Optimize for latency vs depth
Real-time systems differ fundamentally from knowledge assistants.
Prioritize governance and validation
Enterprise AI must include:
Schema validation
Monitoring
Audit trails
Model performance tracking
Treat LLMs as components, not products
LLMs are one layer within a larger AI pipeline architecture.
Designing enterprise-grade GenAI systems
Designing GenAI systems becomes far simpler once we stop treating RAG as a fixed recipe and start treating it as an architectural decision.
The transformation for enterprises lies not in deploying chatbots, but in embedding GenAI pipelines into:
Claims processing
Data governance
Clinical intelligence
Knowledge management
Executive decision support
When input characteristics and output requirements guide the architecture, GenAI evolves from experimentation to infrastructure.
And infrastructure, not demos is what drives durable competitive advantage in the age of Large Language Models.
Recent Blogs

