Why You Should Stop Chasing Prompts and Start Building Better AI Evaluation Systems
As large language models (LLMs) evolve from simple text generators into autonomous AI agents capable of planning, reasoning, memory, and tool usage, a critical question emerges:
How do we evaluate whether LLMs and agentic systems are behaving correctly?
Latency and token counts measure performance speed.
They do not measure:
Whether the answer is factually grounded
Whether retrieval pulled the correct context (RAG evaluation)
Whether the correct tool was selected
Whether the workflow was completed successfully
Whether multi-step agents are executed in the right sequence
This is where LLM Evaluation frameworks become essential.
Evaluation transforms subjective opinions into structured, measurable, and repeatable quality signals, enabling continuous AI improvement rather than endless prompt tweaking.
What Is LLM Evaluation?
LLM Evaluation is a structured framework for measuring the quality, reliability, faithfulness, and workflow behavior of language models and agentic systems in real-world applications.
It evaluates:
Accuracy and answer relevance
Hallucination and factual grounding
Tool selection and execution
Multi-step reasoning workflows
Long-term task completion
Unlike simple accuracy testing, modern AI evaluation frameworks provide scores, feedback, and evidence, enabling continuous improvement loops for LLM-powered systems.
What Is LLM evaluation? A modern AI evaluation framework explained
LLM Evaluation is the systematic process of measuring the performance, reliability, and reasoning behavior of language models and AI agents.
It goes beyond output checking.
It focuses on:
Why a model produced a response
Whether the response was grounded in correct context
How the system behaved across multiple reasoning steps
Whether the agent followed the intended workflow
Evaluation converts opaque model behavior into structured feedback loops.
Instead of:
“This output looks fine.”
You get:
“Faithfulness dropped 12% after the retriever update.”
That shift — from intuition to signals — is what makes evaluation powerful
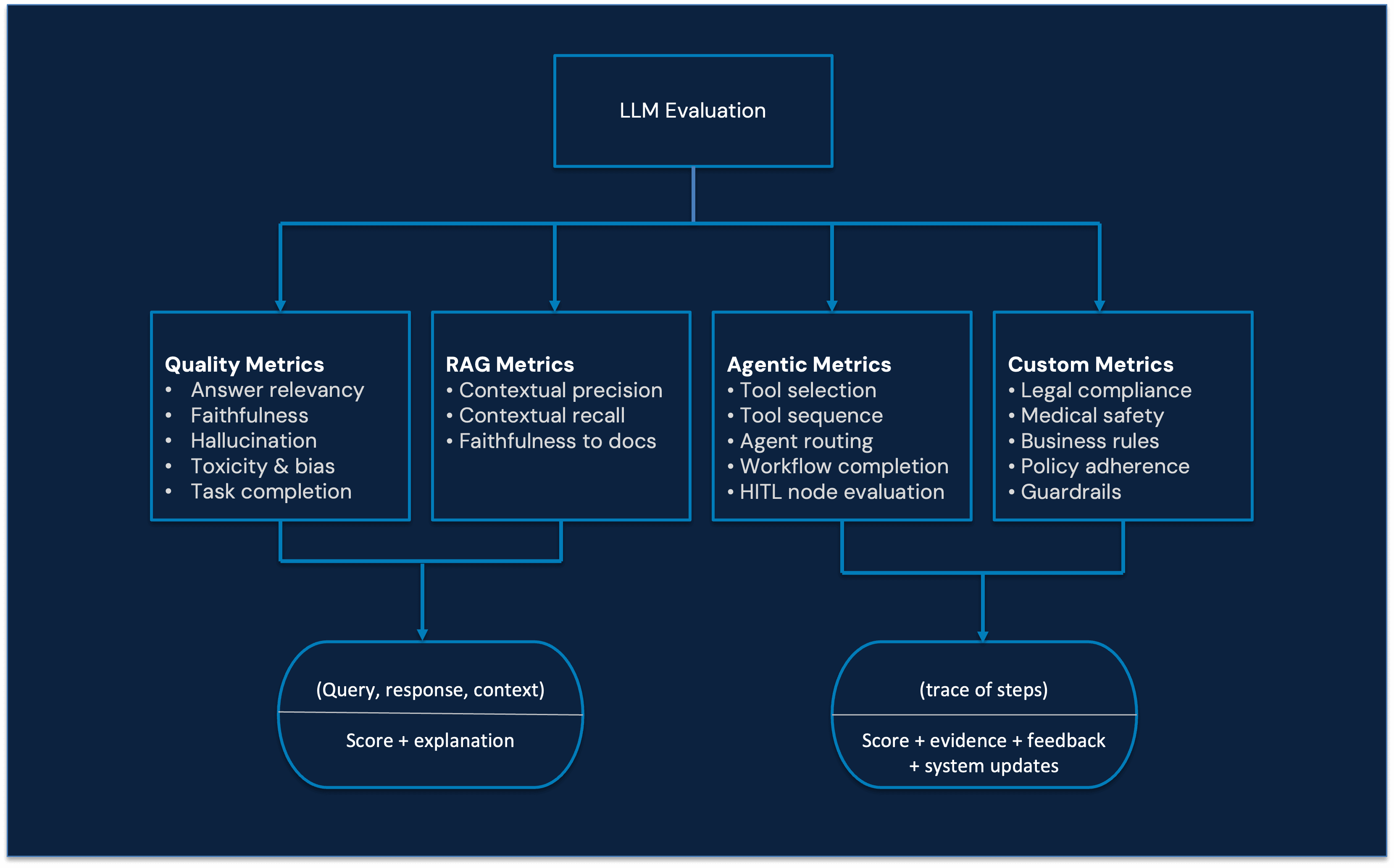
Types of LLM evaluation: Single turn vs multi-turn evaluation
At a high level, AI model evaluation falls into two categories:
Single-Turn (Node-Level) Evaluation
Multi-Turn (Workflow-Level) Evaluation
Both are essential for production-grade AI systems.
Single-Turn Evaluation (Node-Level Evaluation)
Single-turn evaluation assesses an LLM’s performance on isolated question-answer interactions.
It verifies immediate capabilities such as:
Tool selection
Instruction following
Context usage
Hallucination detection
Answer relevance
Common Use Cases:
RAG QA systems
Summarizers
Tool-calling agents
Standalone LLM endpoints
Inputs:
Query
Response
Context
Common Metrics:
Answer Relevancy
Faithfulness (groundedness)
Hallucination Rate
Toxicity & Bias Detection
Evaluation Flow:
Query + Response + Context
↓
Evaluator Model
↓
Score + Explanation
Single-turn evaluation ensures that each component works correctly in isolation.
But modern AI systems are rarely isolated.
Multi-Turn Evaluation (Workflow-Level Evaluation)
Multi-turn evaluation measures how well an agent performs across an entire workflow.
This is critical for:
Autonomous AI agents
Multi-step reasoning systems
Tool-chaining workflows
Agent routing systems
HITL (Human-in-the-loop) systems
It Evaluates:
Tool selection correctness
Tool execution sequence
Agent routing decisions
Workflow completion
Error compounding across steps
Inputs:
Initial query
Full trace (all intermediate reasoning steps)
Tool calls
Routing decisions
Evaluation Flow:
Trace Tree
↓
Evaluator Model
↓
Workflow Score + Reasoning
Prompts
Multi-turn evaluation ensures that agents:
Maintain memory
Avoid cascading errors
Complete long-term goals successfully
Without workflow-level evaluation, autonomous agents become unpredictable.
Why LLM Evaluation Is Critical for Production AI Systems
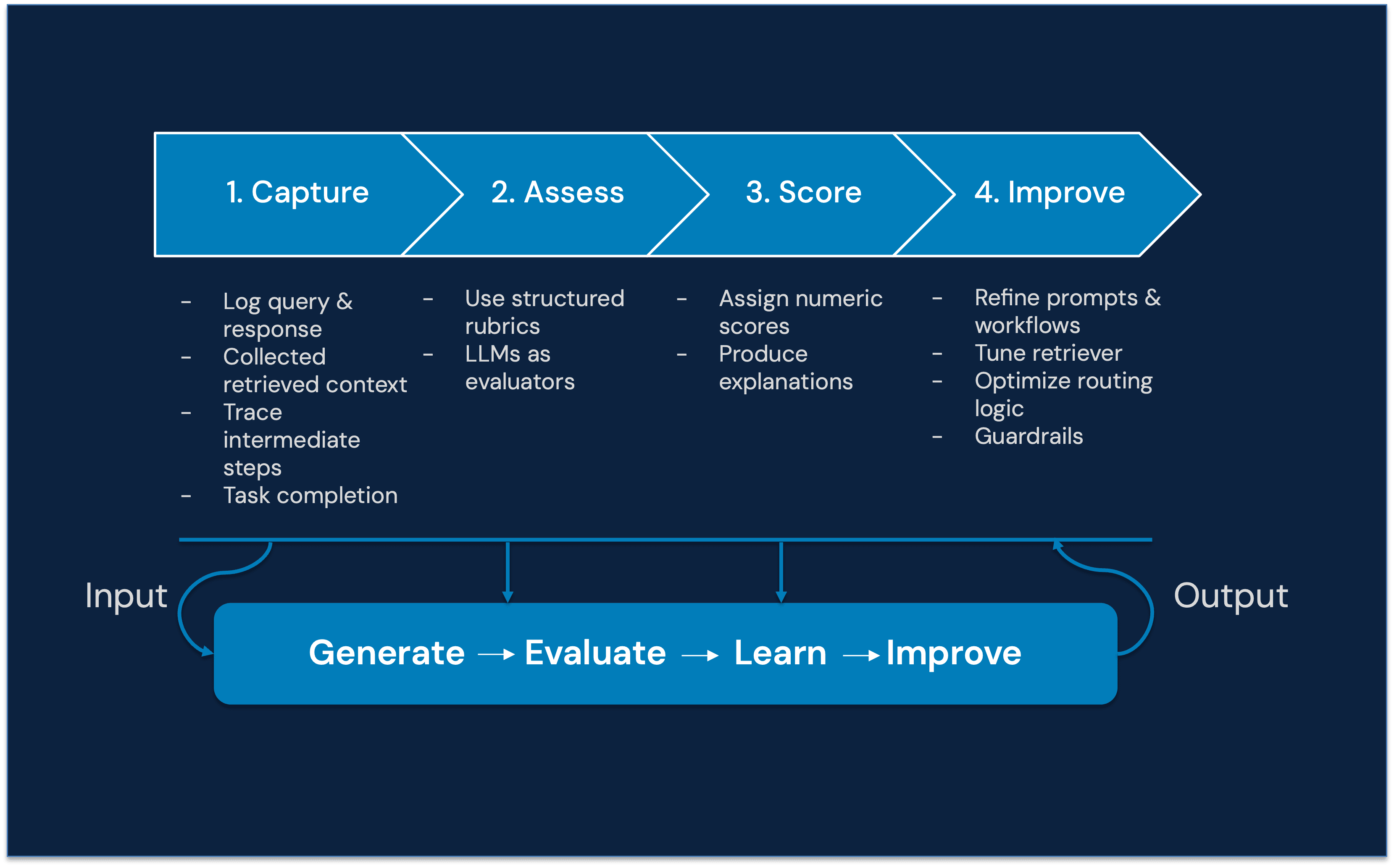
From guesswork to measurable signals
Without structured AI evaluation systems, teams rely on intuition:
“This response looks okay.”
With evaluation frameworks, teams rely on measurable evidence:
“Faithfulness decreased by 12% after retriever changes.”
That difference separates experimentation from engineering.
Beyond accuracy: Modern evaluation must provide evidence and feedback
Modern LLM evaluation frameworks should not stop at numeric scores.
Modern LLM evaluation frameworks should not stop at numeric scores.
They must provide:
Evidence
Which context passages support the answer
Which parts contradict it
Feedback
What went wrong
Where the reasoning broke
Whether the tool was incorrectly selected
Improvement Signals
What to optimize next
Whether to adjust retriever, prompt, or workflow
This transforms evaluation into a continuous learning mechanism, not just a reporting tool.
Evaluation becomes the system that improves the system.
LLM Evaluation in RAG and Agentic Workflows
As RAG (Retrieval-Augmented Generation) systems and agentic AI architectures grow more complex, evaluation must answer deeper questions:
In RAG Systems:
Did the retriever fetch the right documents?
Is the answer grounded in retrieved context?
Is the model hallucinating beyond sources?
In Agentic Systems:
Was the correct tool selected?
Was the tool sequence logical?
Did the agent reach the correct end state?
Did memory persist across turns?
Prompt engineering alone cannot solve these issues.
Only structured LLM evaluation frameworks can.
Evaluation methods + metrics framework
Modern LLM evaluation operates across three complementary methods:
1. Metric-based evaluation (automated)
Used for:
Regression testing
CI/CD pipelines
Large-scale comparisons
Task Type | Metrics | What it measures |
Retrieval (RAG) | Context precision/recall | Relevance of retrieved documents |
Generation | BLEU, ROUGE, BERTScore | Semantic similarity and quality |
Groundedness | Faithfulness, hallucination rate | Alignment with source data |
Safety | Toxicity, bias scores | Risk and compliance |
These metrics provide consistency and scale, but may not fully capture nuanced correctness.
2. Human evaluation
Used for:
Subjective quality assessment
Domain-specific validation
Edge case review
Evaluates:
Helpfulness
Coherence
Contextual accuracy
While highly reliable, this approach is resource-intensive and harder to scale.
3. LLM-as-a-judge
Used for:
Scalable qualitative evaluation
Complex reasoning tasks
Multi-turn and agent workflows
The model evaluates outputs using:
Rubric-based scoring
Pairwise comparisons
Structured prompts
This approach enables scale with depth, but requires careful calibration to mitigate bias.
Key takeaway
Effective evaluation systems combine:
Automated metrics for scale
Human judgment for precision
LLM-based evaluation for flexibility
No single method is sufficient in isolation.
LLM Evaluation Ecosystem: Tools and Platforms
Several tools support AI evaluation, observability, and agent assessment:
DeepEval
Focus: LLM and RAG evaluation
Ragas
Focus: RAG system evaluation metrics
Arize Phoenix
Focus: Observability and agentic workflow evaluation
These platforms help teams:
Track hallucination trends
Monitor faithfulness
Evaluate tool usage
Build regression testing pipelines
Stop Chasing Better Prompts. Build Better Evaluation Systems.
As AI systems become more autonomous, prompt engineering becomes insufficient.
The real competitive advantage lies in:
Structured evaluation pipelines
Continuous feedback loops
Trace-level observability
Workflow-level scoring
Measurable reliability
Evaluation shifts AI development from:
Output tweaking → System design
Just as Atomic Habits emphasizes systems over goals, modern AI development must prioritize:
Evaluation systems over prompt hacks
Implementation workflow (evaluation pipeline)
Step 1: Define success criteria
Align evaluation with system and business goals:
What defines a high-quality response?
What trade-offs are acceptable (accuracy vs. latency vs. cost)?
Which failure modes matter most?
Step 2: Build a golden dataset
Create a representative evaluation dataset using:
Real user queries
Edge cases and failure scenarios
Adversarial prompts
This dataset serves as the foundation for consistent evaluation.
Step 3: Select evaluation methods
Choose the right mix of:
Metrics for repeatability
Human review for critical workflows
LLM judges for complex outputs
Match the method to the task.
Step 4: Integrate into development workflows
Embed evaluation into:
CI/CD pipelines
Prompt and model versioning
Experiment tracking
Every change should be measurable and comparable.
Step 5: Monitor in production
Continuously evaluate live system performance:
Output quality over time
Drift in behavior
Emerging failure patterns
Step 6: Iterate and improve
Evaluation is an ongoing loop:
Update datasets with new edge cases
Refine metrics and scoring criteria
Improve system components (retrieval, prompts, tools)
Key takeaway
LLM evaluation is not a checkpoint, it is a continuous feedback loop that drives system reliability and improvement over time.
Final Takeaway: Evaluation Is the Backbone of Trustworthy AI
If you are building:
Production LLM systems
RAG architectures
Autonomous AI agents
Multi-tool workflows
Then evaluation is not optional.
It is infrastructure.
LLM evaluation frameworks provide:
Groundedness validation
Hallucination detection
Multi-turn workflow verification
Evidence-based feedback
Continuous improvement loops
In the age of agentic AI, evaluation is the real intelligence layer.
What Is LLM Evaluation?
LLM Evaluation is a structured framework for measuring the quality, reliability, faithfulness, and workflow behavior of language models and agentic systems in real-world applications.
It evaluates:
Accuracy and answer relevance
Hallucination and factual grounding
Tool selection and execution
Multi-step reasoning workflows
Long-term task completion
Unlike simple accuracy testing, modern AI evaluation frameworks provide scores, feedback, and evidence, enabling continuous improvement loops for LLM-powered systems.
Recent Blogs

