Modernizing Microsoft SQL Server to Databricks: A Practical Lakehouse Migration Blueprint
Enterprise data teams are under pressure to deliver faster reporting, governed self-service analytics, real-time insights, and AI-ready data products. Despite this, many organizations still depend on Microsoft SQL Server environments that were built for a different era of enterprise data.
These platforms have powered reporting, departmental data marts, stored procedures, and SSIS-based ETL for decades. They remain business-critical, but they often struggle as data volumes grow, and business users expect near real-time analytics, machine learning, GenAI, and trusted access to data across functions.
As a result, SQL Server-centric architectures often create four practical challenges:
Limited scalability: Performance tuning becomes more complex as data volumes, user demand, and reporting workloads grow.
Higher operating costs: Teams spend more time maintaining infrastructure, optimizing workloads, and supporting legacy patterns.
More data duplication: Data gets copied across marts, reports, and downstream systems, which makes consistency harder to maintain.
Fragmented governance: Access, lineage, and business definitions remain scattered across databases, jobs, reports, and security models.
These issues do not make SQL Server less valuable. They show why many enterprises need a modern data platform that can support both current analytics and future AI use cases.
Therefore, migrating from SQL Server to Databricks is not just database migration. It is an opportunity to modernize the data estate into an open, scalable and governed Lakehouse platform built for analytics, AI, and future-ready data products.
Why enterprises are moving from SQL Server to Databricks
Many organizations still rely on SQL Server for operational reporting, departmental data marts, SSIS packages, SQL Agent jobs, and complex stored procedures. These systems often contain years of embedded business logic and operational knowledge. That makes migration sensitive, but it also creates an opportunity to simplify and modernize the data foundation.
Common challenges in legacy SQL Server estates include scalability limits, inconsistent performance, rising infrastructure and licensing costs, data duplication, tightly coupled ETL processes, and limited support for modern AI and machine learning workloads. For business leaders, these challenges show up as slower decision cycles, delayed analytics releases, and higher dependency on specialized technical teams.
Databricks helps enterprises move beyond legacy data warehouse patterns by unifying data engineering, analytics, BI, machine learning, streaming, and GenAI on a single Lakehouse platform. With Delta Lake, Unity Catalog, Databricks SQL, Lakeflow, and AI/BI capabilities, organizations can build a governed and high-performance data platform that supports current analytics needs and future AI use cases.
Migration is modernization, not lift-and-shift
A successful SQL Server to Databricks migration should not simply copy tables and rewrite code line by line. It should redesign the data platform for cloud-scale analytics, governed data sharing, and reusable data products.
Typical mappings include:
SQL Server | Databricks Lakehouse |
|---|---|
SQL Server Database | Unity Catalog Catalog |
SQL Server Schema | Unity Catalog Schema |
SQL Server Table | Delta Table |
SQL Agent Job | Lakeflow Job |
SSIS Package | Lakeflow Job / Lakeflow Pipeline / ADF |
Stored Procedure | Databricks SQL / PySpark / Notebook |
SQL Server Security | Unity Catalog Groups, Privileges, Row Filters, and Column Masks |
SQL Server Audit | Unity Catalog Audit and System Tables |
This modernization approach helps reduce technical debt, improve governance, simplify operations, and create a stronger foundation for analytics and AI.
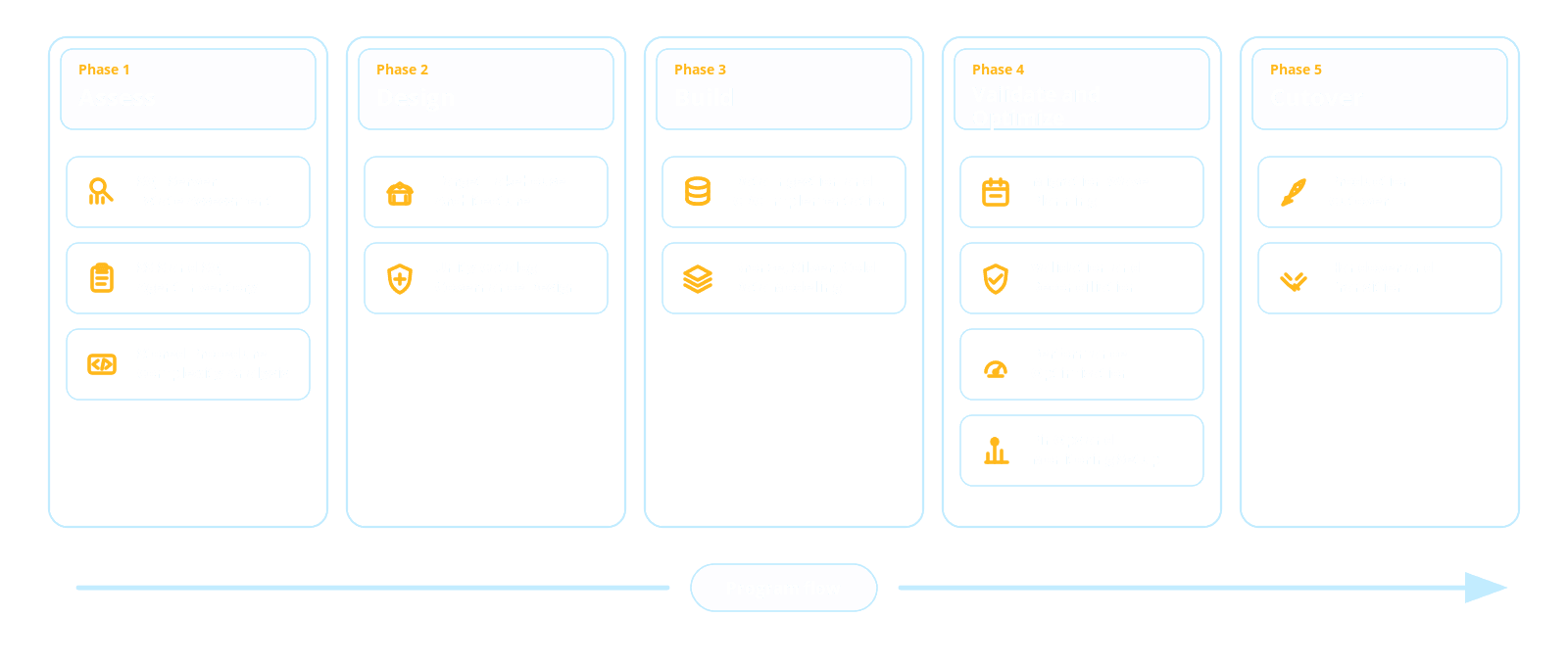
A step-by-step blueprint for SQL Server to Databricks migration
The migration should follow a clear sequence. Each step should reduce risk, preserve business continuity and move the organization closer to a governed Lakehouse architecture.
Step 1: Assess the SQL Server estate
Start with a structured assessment of the SQL Server estate. This includes databases, schemas, tables, views, stored procedures, functions, SQL Agent jobs, SSIS packages, linked servers, security roles, data volumes, and reporting dependencies.
The assessment should also classify migration complexity. Simple SQL views and ANSI-compatible queries may convert easily. Dynamic SQL, cursors, CLR objects, linked servers, OPENQUERY, OPENROWSET, and SSIS Script Tasks typically require redesign because they often depend on procedural execution, external calls or SQL Server-specific behavior.
A practical assessment should answer five questions:
What data and logic are still actively used?
Which workloads are candidates for direct conversion?
Which workloads need redesign for Spark, Delta and Lakehouse patterns?
Which reports, dashboards, and downstream applications depend on each object?
What validation, reconciliation, and cutover controls are required before production migration?
Databricks Lakebridge supports migration assessment, SQL conversion, validation, and reconciliation. This helps teams reduce risk and accelerate migration planning.
Step 2: Define the target Lakehouse architecture
After assessment, define the target architecture. A modern SQL Server to Databricks architecture usually follows the below medallion pattern.

Bronze stores raw ingested data. Silver applies cleansing and standardization. Gold delivers business-ready datasets for reporting, dashboards, AI/ML and downstream applications.
For business teams, this pattern creates clearer ownership and trust. Raw data remains available for audit and traceability. Standardized data supports reusable analytics. Curated data gives executives, analysts, and AI applications consistent business definitions.
Step 3: Choose the right ingestion strategy
Once the target architecture is clear, select the ingestion strategy. The right approach depends on data volume, latency, source system load, and business requirements.
For large historical loads, bulk export from SQL Server into cloud object storage can be used to initialize Bronze tables. This approach works well when teams need to move large volumes of existing data into Delta tables before enabling incremental synchronization.
For ongoing incremental loads, Change Tracking or Change Data Capture can keep Databricks synchronized with SQL Server. Databricks Lakeflow Connect supports SQL Server ingestion and can use Change Tracking or CDC to process source changes. Databricks recommends Change Tracking for tables with primary keys to reduce source database load where applicable.
For analytics-first migration, Lakehouse Federation can provide immediate read access to SQL Server data from Databricks without copying all data upfront. This is useful during transition phases, parallel runs, and phased modernization. It also gives teams a practical way to compare source and target outputs while business users continue to access trusted data.
Step 4: Modernize SSIS, SQL Agent, and T-SQL logic
After ingestion planning, review the workloads around the data. SQL Server migrations often involve much more than tables. SSIS packages, SQL Agent schedules, stored procedures, and reporting logic must be reviewed and modernized.
Recommended modernization patterns include:
Legacy SQL Server Estate | Modern Databricks Lakehouse |
|---|---|
SQL Agent Jobs | Lakeflow Jobs |
SSIS Control Flow | Lakeflow Jobs Orchestration |
SSIS Data Flow | Lakeflow Pipelines / PySpark / SQL Transformations |
Stored Procedures | Databricks SQL / PySpark / Lakeflow Pipelines |
Staging Tables | Bronze and Silver Delta Tables |
Reporting Marts | Gold Delta Tables and Databricks SQL |
Not all T-SQL should be migrated as-is. Standard SELECT, JOIN, GROUP BY, CTE, and window-function logic usually transfers well. Procedural code, cursors, dynamic SQL, temp-table-heavy logic, and SQL Server-specific features often benefit from redesign into scalable Spark and Delta patterns.
The goal is not to preserve every implementation detail. It is to preserve business logic while improving scalability, maintainability, and governance.
Step 5: Build governance with Unity Catalog
Governance should be designed from the beginning of the migration. It should not be added after data has already moved.
Unity Catalog provides the foundation for centralized access control, metadata management, lineage, auditability, and data discovery across Databricks.
A strong governance model should include the following components:
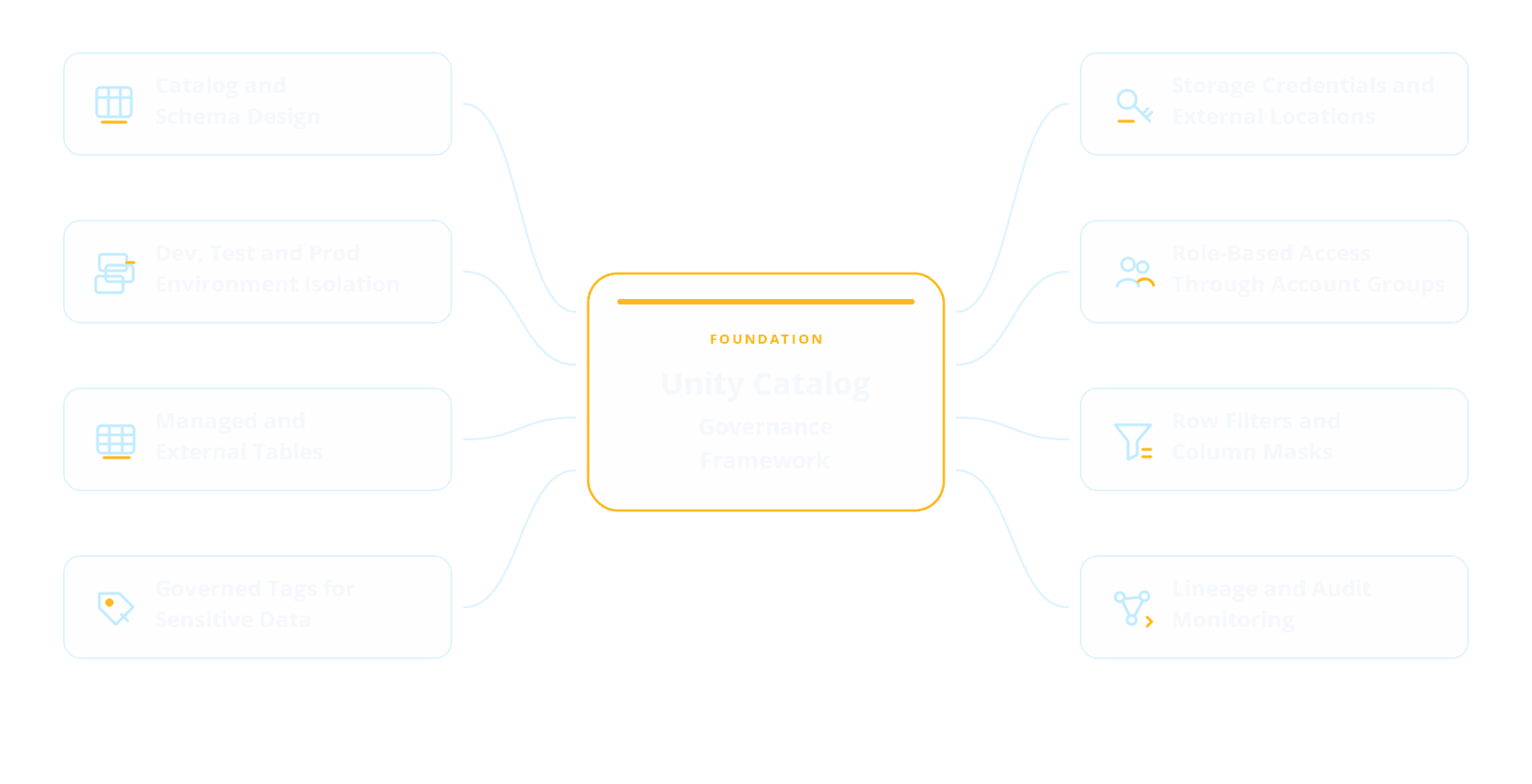
This helps organizations migrate securely while improving visibility and control across the data estate.
For business leaders, governance is also a value enabler. It allows more teams to use data with confidence while reducing the operational risk that often comes from uncontrolled data copies, inconsistent metrics, and unclear ownership.
Step 6: Optimize for performance and cost
After core data movement and governance patterns are defined, design for performance and cost. SQL Server performance patterns do not map one-to-one to Databricks. Indexes, filegroups, and stored procedure tuning are replaced by Lakehouse-native optimization techniques.
Key design considerations include:
Data Layout and Storage Optimization | Compute and Workload Efficiency | Observability and FinOps |
|---|---|---|
Delta Table Layout | Photon Execution Engine | System Billing Tables for Chargeback |
Liquid Clustering or Partitioning | Serverless SQL Warehouses | Query History and Performance Monitoring |
OPTIMIZE and File Compaction | Job Clusters with Auto-Termination | |
Workload Tagging |
The goal is to design for elastic compute, optimized storage, predictable performance, and measurable cost control.
Step 7: Validate, reconcile, and cut over
Enterprise migration success depends on trust. Every critical dataset should go through validation and reconciliation before cutover.
Validation should include:
Structural Validation | Business Reconciliation | Cutover Consistency |
|---|---|---|
Schema comparison | Aggregate reconciliation | CDC consistency checks |
Row counts | Financial total comparison | |
Null checks | Query result comparison | |
Duplicate checks | Dashboard comparison | |
Min / Max validation |
A typical cutover plan includes initial bulk load, incremental sync, parallel run, business validation, final delta load, production switch, rollback planning, and controlled SQL Server decommissioning.
Lakebridge also supports reconciliation capabilities to help validate migrated data and reduce migration risk.
Step 8: Extend the platform for AI-ready data products
The biggest value of migrating to Databricks is not only lower cost or faster reporting. It is the ability to create an AI-ready data foundation.
Once SQL Server data is modernized into the Lakehouse, organizations can unlock:
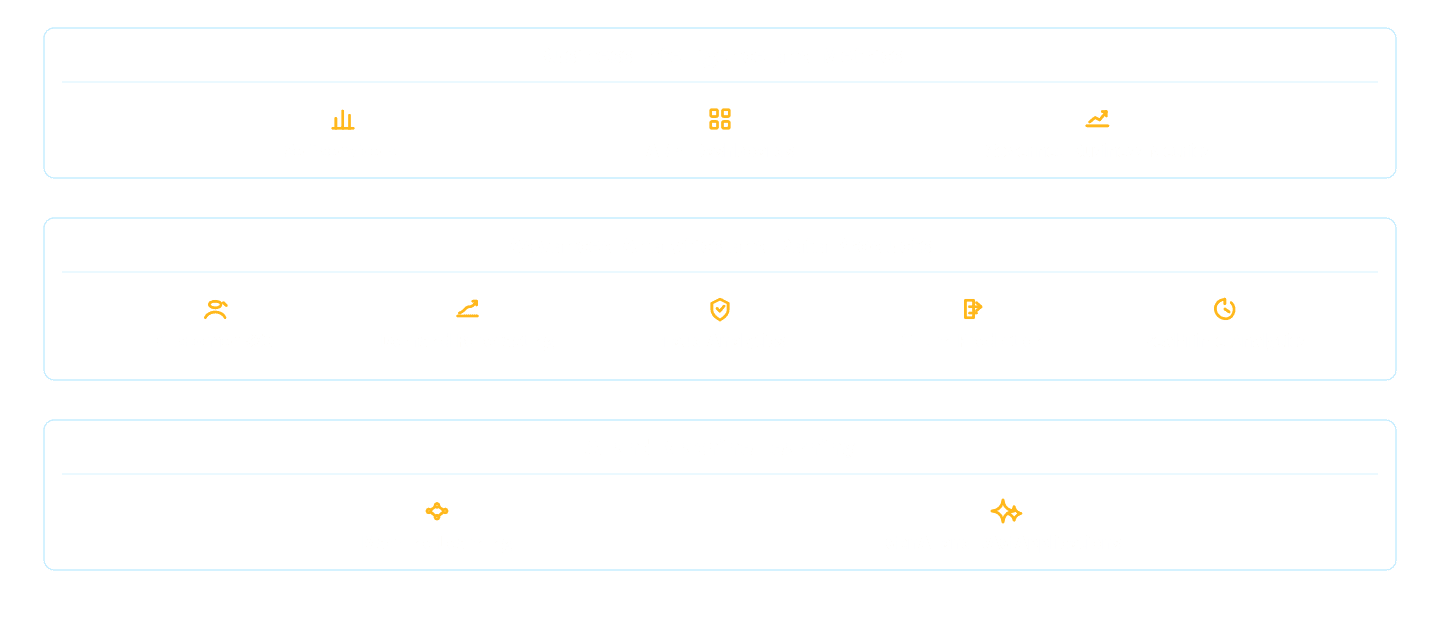
Unity Catalog metric views now provide a governed way to define business metrics centrally and reuse them consistently across analytics and AI use cases. This is important for organizations that want AI outputs, dashboards, and reports to rely on the same approved business definitions.
How a Databricks partner accelerates the journey
As a Databricks partner and systems integrator, Fractal helps enterprises reduce migration risk and accelerate modernization. Our approach combines assessment, architecture, migration automation, data engineering, governance, validation, performance tuning, and operational readiness.
We help organizations move beyond object conversion and build a secure, scalable, cost-optimized Lakehouse foundation that supports analytics, AI, and future data products.
Our SQL Server to Databricks migration approach includes:
Conclusion
Migrating from Microsoft SQL Server to Databricks is a strategic modernization opportunity. With the right assessment, architecture, ingestion strategy, governance model, and validation framework, enterprises can move from legacy SQL Server reporting and ETL into a modern Lakehouse platform built for trusted analytics and AI.
The organizations that succeed are those that treat migration not as a lift-and-shift exercise, but as a platform transformation journey. By modernizing data, pipelines, governance and business logic together, enterprises can build a more scalable foundation for decision intelligence, AI adoption, and future data products.
Recent Blogs

