TL;DR:
Analytical platforms hold the trusted data real-time applications need, but they are built for scale, throughput and analysis, not millisecond transactional response.
Databricks Lakebase closes the gap by adding a fully managed, Postgres-compatible operational tier next to governed Lakehouse data.
Lakebase simplifies the architecture, but it does not remove the need for disciplined production design.
Every industry has its own version of the same high-pressure moment. A retailer races to sell limited stock in a flash sale. A pricing engine refreshes offers as demand shifts. The industries differ, but the requirements stay the same. Each application has to act on trusted data in milliseconds. When it cannot do that, the cost is immediate. Shoppers abandon carts, recommendations go stale, and inventory oversells.
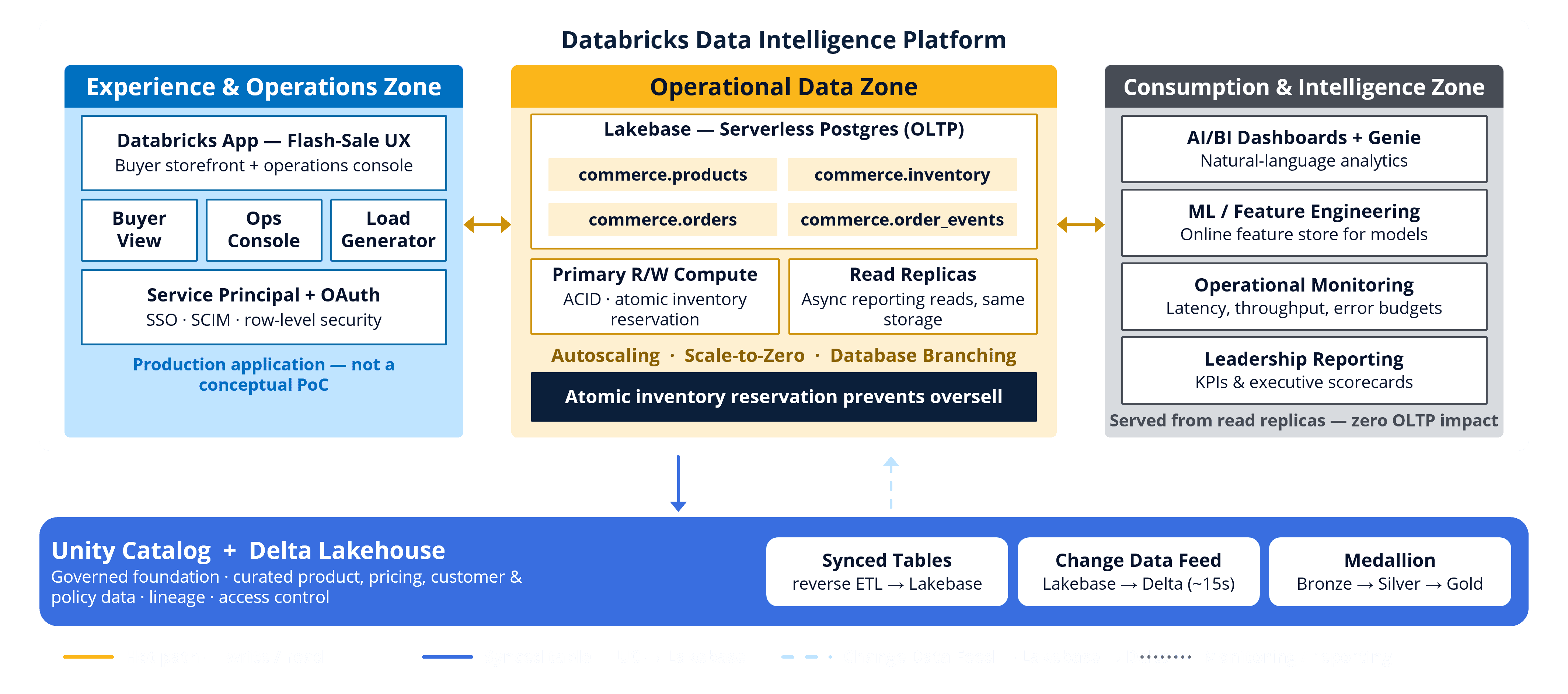
This is not a niche problem. It is a repeatable pattern that calls for more than a one-off fix. That pattern runs on Databricks Lakebase, the fully managed operational database that lives inside the Databricks Platform.
Why Lakehouses cannot serve real-time operational workloads
Your organization’s Lakehouse already holds the data that matters. The trusted product catalog, customer profile, and pricing intelligence all sit in one governed place. However, when a user acts, that data only matters if the application can respond in milliseconds.
Analytical workloads need scale while operational workloads need low latency
The gap comes from a mismatch in what each platform is built to do. Modern data platforms handle analytics exceptionally well. Analytical engines such as Delta Lake, Spark and SQL Warehouses are built for scale, throughput, and complex aggregations. Operational workloads require a different set of capabilities. They need low-latency lookups, atomic writes, transactional consistency, and steady performance when traffic spikes.
That gap becomes most visible in personalization, pricing, inventory, agent state, and flash-sale scenarios, and it cuts across every industry that runs them. The data lives in the Lakehouse, but the application still needs a fast transactional database to serve every request in real time. Without that database, the gap shows up as customer-visible latency, decisions made on stale data, and sales lost at peak demand.
Lakebase adds Postgres transactions next to Lakehouse data
Databricks Lakebase closes this gap. It brings a fully managed, Postgres-compatible operational database into the Databricks Platform, with support for transactional workloads, autoscaling, read replicas, branching, OAuth-based authentication, and integration with Unity Catalog and synced tables.
Since the operational store sits next to the Lakehouse, applications can work from the same governed data the business already trusts, with no second copy to reconcile and no separate database estate to run.
Lakebase handles transactions while the Lakehouse handles analytics
The architecture has two tiers inside one platform. One tier serves live application requests, and the other continues to power analytics, ML, and governance. That separation matters because real-time applications need low-latency transactions, while analytical workloads need scale, throughput and historical context.
Lakebase runs as the hot operational tier, handling transactional reads, writes, reservations, and event capture.
The lakehouse remains the analytical tier, powering aggregations, BI, ML, historical analysis and governance.
Each engine focuses on the workload it does best, while the business governs and secures both from one platform.
Key advantages of separating the two tiers
Operational and analytical layers stay connected: Lakebase brings Postgres-compatible operational workloads closer to governed Lakehouse data. Rather than copy curated data into an outside database and maintain custom sync logic, teams use Databricks-native patterns such as synced tables and Lakehouse connectivity. This keeps a single, consistent copy instead of duplicates that drift apart across systems.
Security follows platform identity: Databricks Apps run under a dedicated service principal identity. Combined with OAuth-based access, this removes static database passwords and makes auditing, authorization, and credential management cleaner, which shortens audits and reduces the risk of a leaked credential.
Branching speeds up engineering: Database branches let teams test schema changes, indexes, and migrations in isolated environments before they touch production. For operational systems, where a small schema change can swing latency and concurrency, teams ship those changes with far less risk to live traffic.
Read replicas keep workloads apart: Teams route reporting, monitoring, and dashboard queries to read-only endpoints, which takes pressure off the primary write endpoint. Heavy analysis never slows the write path that customers depend on during a surge.
The platform carries the infrastructure load: Databricks handles much of the database operations lifecycle, which lets engineering teams focus on application design, transaction semantics, observability, and user experience instead of running a separate Postgres estate. That lowers the total cost of ownership and shortens the time to launch.
Applying the pattern to a retail flash sale
To put the pattern under real pressure, Fractal's engineering team built it for one of the most demanding retail moments, the flash sale. At its peak, thousands of buyers hit the same product page in the same second, each trying to claim the last unit in stock. The application has to reserve inventory, confirm the order, and update availability before the next shopper refreshes the screen. Even a brief delay is the difference between a completed sale and an oversold order.
The team built the platform as a single Databricks App using Streamlit on managed compute, spanning the buyer journey, the transactional path, operational monitoring, and data movement.
The five components of the application
The application comes together from these working pieces:
The buyer view: Delivers a real-time product and inventory experience that serves low-latency customer interactions straight from the operational layer.
The ops dashboard: Gives operations teams a live view of orders, inventory, latency, and workload behavior, all without leaning on the transactional path.
The load generator: Simulates demand on-command, so the team can watch the application behave under flash-sale pressure before real customers do.
The bulk data seeder: Creates meaningful historical and operational data on demand, so dashboards, analytics, and test scenarios run against realistic volumes.
The implementation blueprint: Shows how the app, Lakebase, Unity Catalog, synced data, and downstream analytics work together as one pattern.
Handling inventory changes as a single transaction
The components above describe what the application does. However, keeping its data correct under load is a separate design challenge. The Fractal Engineering team gave the application its own dedicated schema, which keeps operational data separated, governed, and easy to manage. This avoids default database areas and makes ownership, permissions, and lifecycle clear from day one.
It’s important to note that the app handles inventory changes as a single controlled transaction rather than a string of separate steps. That is what stops two buyers from claiming the same last unit. It protects revenue, keeps the customer experience consistent, and shows an operational database doing real-time work while the Lakehouse keeps serving analytics.
Five takeaways from taking the pattern to production
The flash-sale example demonstrates that platform capability can get you started, but disciplined configuration, identity, access, and observability decide the outcome. Here are a few key takeaways:
Run the app the right way: Databricks Apps provide a managed runtime, but the application still needs the right launch and deployment configuration to perform. Treat startup and deployment as part of the architecture, not a last-minute chore.
Keep configuration clean and secure: The team kept connection details and environment settings out of the application logic, which made the app easier to move, secure, and operate.
Use platform identity, not static passwords: The application relied on platform identity patterns instead of static database passwords. That keeps the implementation secure, auditable, and in step with enterprise identity standards.
Get the access model right: The team gave the application identity exactly the access it needed at the correct database and schema level, and it avoided default database areas. Explicit schemas and permissions, rather than defaults, strengthen security, governance, and operational clarity.
Surface problems early: The app shows meaningful diagnostics during startup, connection, and data access. Build observability in from the start, because clear logging makes any application easier to support, troubleshoot, and carry toward production.
These takeaways are from a retail build, but they are not unique to retail. Strip away the retail labels, and the same moving parts remain:
A hot operational tier handles fast writes while a governed Lakehouse feeds it trusted data.
A single controlled transaction protects integrity, and live visibility shows how the system behaves under load.
Swap inventory for a pricing table, a recommendation set or an agent’s memory, and the pattern still holds. That makes the approach industry-agnostic.
Databricks Lakebase removes the friction, not the need for design discipline
Databricks Lakebase works in this pattern because it adds the operational layer the Lakehouse was not designed to provide. It keeps real-time workloads close to governed data and gives developers familiar Postgres patterns for reads, writes, and transactions.
The flash-sale reference application proves the pattern in practice by combining live inventory reservation, simulated demand, operational visibility, historical data seeding, and Lakehouse integration. For teams building real-time applications, agent memory, feature-serving APIs, personalization services, or transaction-heavy workflows, Lakebase can simplify the architecture.
However, it does not replace disciplined design. Production success still depends on workload isolation, release management, security, monitoring, and data synchronization, no matter which industry runs on top.
Recent Blogs

