Generative AI has been transformative across industries, helping businesses to accomplish tasks quicker and more efficiently than ever before. It has been used to create text and visual content, get answers to questions, generate code, and more. Though generic large language models (LLMs), such as the models available through Google Cloud Vertex AI, are incredibly robust and valuable for accomplishing a variety of tasks, there are techniques that organizations can use to improve the quality of their computer-generated content.
Starting with the end-user, the first method of improving the output of generative AI is to craft the perfect prompt through so-called prompt engineering. Organizations can also help their users get more precise output by governing the LLMs themselves. There are two ways an organization could do this by combining approaches across two axes:
- Context optimization: Providing more specific and detailed information for the LLM to draw from.
- LLM optimization: Adapting the LLM to accomplish specific tasks or work within a given domain.
Let’s go into more detail about how organizations can maximize the effectiveness of their generative AI applications below.
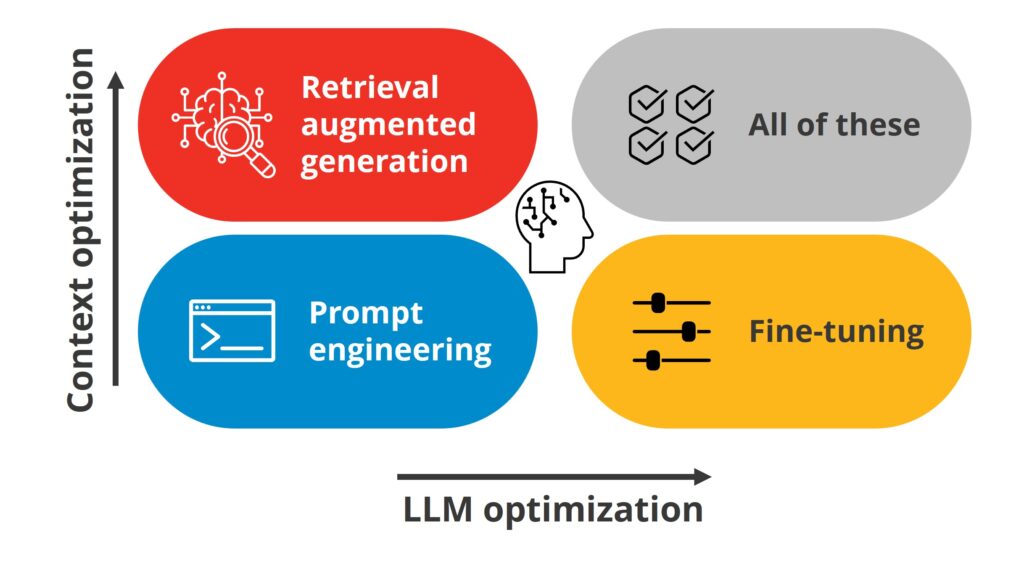
Prompt engineering
Prompt engineering refers to crafting specialized and effective prompts to guide language models and optimizing the context for the desired outputs. Put simply, that means writing the prompt in a way to get exactly what is expected. Here are five guidelines to help end users with their prompt writing.
- Be specific and contextualize: Clearly define the topic and provide context. Specify the audience, tone, and timeframe. The more precise the prompt, the better the AI’s response will be.
- Iterate for refinement: Use an iterative approach. Refine the prompt based on initial outputs. Adjust and experiment to get more useful information.
- Include an action or task: Add an action or task for the AI to complete. For instance, ask it to summarize, outline, list, plan, compare, or predict. This helps guide the AI toward a specific outcome.
- Set parameters: Specify parameters such as word count, exclusions, or formatting preferences (e.g., subheadings, paragraphs). This ensures the AI generates content that aligns with the end-user’s requirements.
- Avoid bias: Be mindful of bias. Biased prompts can lead to biased outputs. For example, asking a leading question may produce a skewed answer. Aim for balanced prompts that explore both sides of an issue.
Prompt engineering is a practice that is accessible to end users in any generative AI product they use, whether those products use general LLMs or those managed by their organization via Vertex AI.
From an organizational perspective, companies can help end-users maximize the use of their GenAI apps by providing instruction and guidance on how to properly craft prompts for a given task. Generative AI is a new technology that many end-users are still getting used to. Giving them resources to learn more quickly is one of the best ways to help them get the most out of the app.
Context Optimization: Retrieval Augmented Generation (RAG)
To further increase the quality and usefulness of AI-generated content, organizations can also provide LLMs with additional information before the prompt so that the LLM executes prompts in a certain way. Called Retrieval Augmented Generation (RAG), this method allows organizations to pre-define the scope or context of the prompt. Here is an example of how it might be used in real life.
Scenario:
Imagine you are an executive at an electronics company that sells devices like smartphones and laptops. Your company wants to provide detailed answers about its products to customers, journalists, and investors. You have a vast knowledge base containing information about various product specifications, features, and use cases.
Customer Query: “What makes our latest smartphone stand out?”
Without RAG:
In this scenario, without RAG the LLM can produce a result on the prompt, however, the LLM lacks specific details about your products beyond what it learned during training.
Response (without RAG): “Our latest smartphone is a great device. It has a powerful processor, a nice display, and a good camera. The battery life is decent too.”
Using RAG:
By incorporating the knowledge base into the LLM’s prior knowledge, when you ask the LLM a question about a specific product, it can retrieve relevant information from the knowledge base and integrate it into the generated response. The result is a much more targeted and specific response.
RAG-Enhanced response: “Our latest smartphone boasts a powerful Snapdragon processor, a stunning AMOLED display, and a triple-camera setup for exceptional photography. Additionally, its long-lasting battery ensures uninterrupted usage throughout the day.”
RAG can be enabled through various approaches, and Google’s Vertex AI offers multiple tools that can be used depending on the selected approach.
LLM optimization: Fine-Tuning
To further improve the results of generative AI responses, organizations can fine-tune pre-trained LLM models to specific tasks and domains. There are three ways they can approach this customization:
Supervised Learning Fine-Tuning:
- In supervised learning, organizations provide a predefined correct answer (ground truth) for a specific task.
- The LLM is then fine-tuned using labeled data to generate more accurate and contextually relevant responses.
- For example, if an organization wants to create an LLM for code completion, they can fine-tune it using a dataset of code snippets and their corresponding completions.
Reinforcement Learning from Human Feedback (RLHF):
- RLHF involves training the LLM based on feedback from human evaluators.
- Human evaluators rank different model responses based on quality, relevance, and correctness.
- The LLM learns from this feedback to improve its performance over iterations.
- RLHF is particularly useful when there is no predefined correct answer, as it allows the model to learn from human preferences and adapt accordingly.
Domain-Specific Fine-Tuning:
- Organizations can fine-tune LLMs on domain-specific data.
- For example, a healthcare organization can LLM fine-tuned on medical texts to provide accurate diagnoses or treatment recommendations.
- Similarly, in finance or technology, fine-tuning on relevant data enhances the LLM’s utility for specific tasks.
This fine-tuning strikes a balance between generalization and specialization, allowing LLMs to excel in specific contexts while retaining their overall capabilities.
Organizations can fine-tune LLMs for their users by using Vertex AI.
Putting it all together
Of course, these techniques aren’t mutually exclusive. You could use one or both of them depending on your needs and the resources available in your organization.
If you are looking for help in putting the pieces together, Fractal experts can help you plan and implement a solution that will work for you.
Contact us to learn more.

