Default 200 shuffle partitions
Generally speaking, partitions are subsets of a file in memory or storage. However, Spark partitions have more usages than a subset compared to the SQL database or HIVE system. Spark will use the partitions to parallel run the jobs to gain maximum performance. While we operate Spark DataFrame, there are majorly three places Spark uses partitions which are input, output, and shuffle.
Input and output partitions could be easier to control by setting the maxPartitionBytes, coalesce to shrink, repartition to increasing partitions, or even set maxRecordsPerFile, but shuffle partition whose default number is 200 does not fit the usage scenarios most of the time. This blog will introduce general ideas about how to set up the right shuffle partition number and the impact of shuffle partitions on Spark jobs.
e.g. input size: 2 GB with 20 cores, set shuffle partitions to 20 or 40
e.g. input size: 20 GB with 40 cores, set shuffle partitions to 120 or 160 (3x to 4x of the cores & make each partition less than 200 MB)
e.g. input size: 80 GB with 400 cores, set shuffle partitions to 400 or 800.
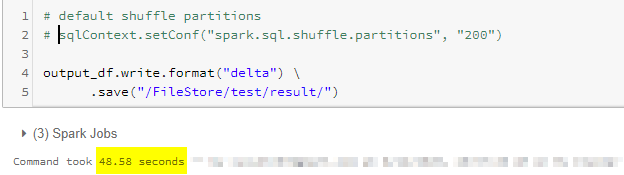
Here is an example of how to improve the performance by simply changing the number of partitions on a small DataFrame working with a limited size of cluster (8 cores total).
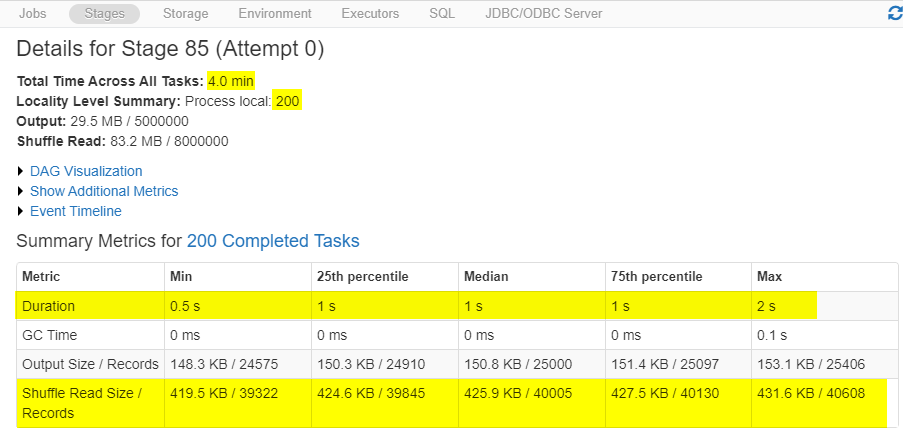
200 is way too much for this size of data and size of a cluster. It takes longer to allocate the jobs to finish all 200 jobs.
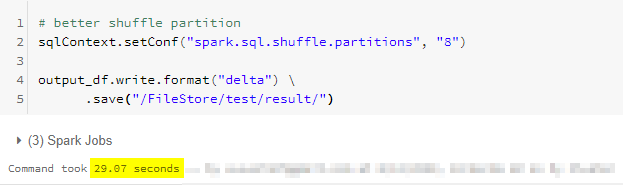
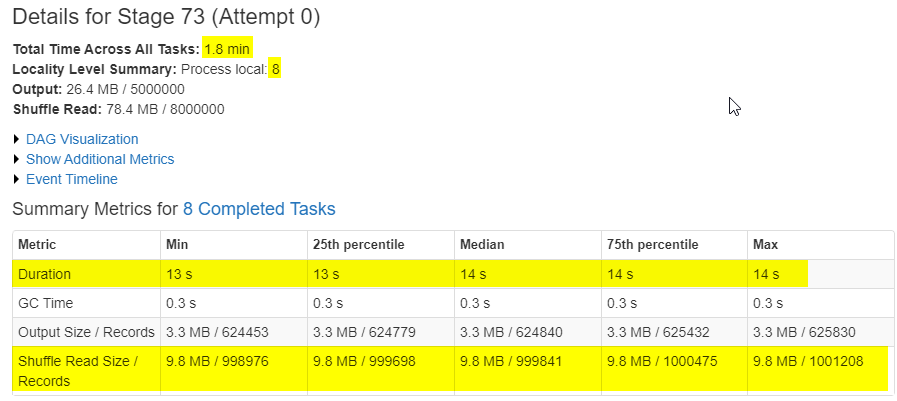
By simply changing the # of shuffle partitions without changing anything else, the process is running about 40% faster than the default.
The first and most important thing you need to check while optimizing Spark jobs is to set up the correct number of shuffle partitions. The number of shuffle partitions will not only solve most of the problems but also it is the fastest way to optimize your pipeline without changing any logic.
The example was using a small DataFrame with a limited cluster, which does not need to consider the size of each partition and has no skew keys. While optimizing a larger DataFrame, the solution will also include checking the size for each partition and making sure each partition is well distributed.
The ideal size of each partition is around 100-200 MB. The smaller size of partitions will increase the parallel running jobs, which can improve performance, but too small of a partition will cause overhead and increase the GC time. Larger partitions will decrease the number of jobs running parallel and leave some cores ideal by having no jobs to do. If you also have a skew key issue, try to add a dummy column and force Spark to partition on the well-distributed dummy column while partitioning then drop the dummy column while writing.
Check out this latest tutorial: Databricks Spark jobs optimization techniques: Multi-threading .

