“Data is the new oil” is a phrase we’ve heard countless times, but just like unrefined oil, raw data lacks value until it’s processed. The real challenge lies in refining that data into something useful. This is where AWS Glue Data Quality comes into play, offering a powerful solution to turn raw data into actionable insights quickly and efficiently.
There are frameworks that can help filter and present usable data, or you can take the coding route to develop a custom data quality framework. However, both of these approaches require investment in significant resources. AWS Glue Data Quality solves this issue by enabling anyone to build a robust data quality pipeline quickly and easily, without needing specialized skills.
AWS Glue Data Quality offers several compelling benefits that make it a preferred choice for data quality management:
- Quick builds: AWS Glue Data Quality quickly analyzes your data and creates data quality rules for you in just two clicks. “Create Data Quality Rules –> Recommend Rules.”
- In-build/reusable rules: With 25+ out-of-the-box Data Quality (DQ) rules to start from, you can create rules that suit your specific needs.
- Evaluating data quality: Once you evaluate the rules, you get a data quality score that provides an overview of the health of your data. Use data quality scores to make confident business decisions.
- Pay as you use: You only pay for what you use, making it a cost-effective solution.
- No language barrier: AWS Glue Data Quality is built on open-source Deequ, allowing you to keep the rules you are authoring in an open language.
Now that we’ve discussed the benefits, let’s dive into a practical example to see AWS Glue Data Quality in action.
1. Mocking up our data pipeline: Setting the stage
Let’s define our datasets and their roles in the pipeline.
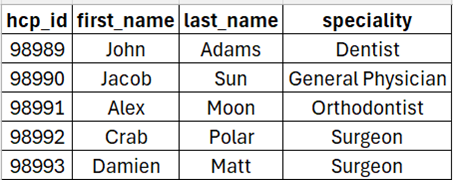
a) We have two datasets; one describes all the unique doctors we have in our database, let’s call it “HCP Dataset”.
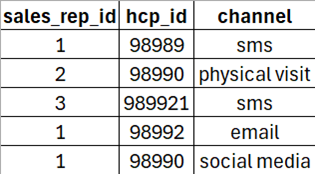
b) Another is a dataset containing information on sales rep interactions with unique doctors and the channel they used. Let’s call it “Sales dataset”.
c) Now, let’s say we want to configure rules like:
i. “hcp_id” in the “HCP Dataset” should be unique.
ii. “hcp_id” in “Sales dataset” should match with “hcp_id” in “HCP Dataset”
iii. And so on….
2. Getting Started with AWS Glue’s Data Quality feature
Now, let’s get our hands dirty with AWS Glue:
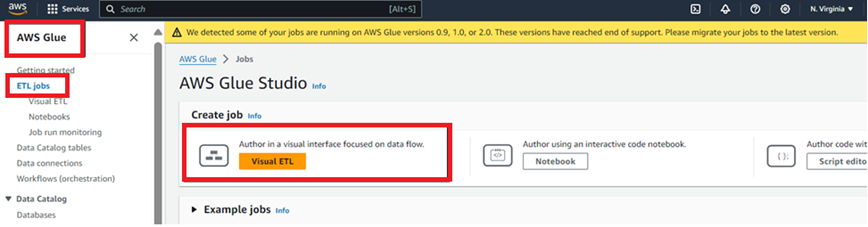
iv. Log onto your AWS Account and open AWS Glue console.
v. Select ETL Jobs from the left tree and select the “Visual ETL” option as depicted in the screenshot below:
vi. This gives you a blank canvas to work with, so let’s get to work!
vii. First, let’s configure our input– the two datasets we discussed earlier.
From sources, select Amazon S3 and configure details like the “Source Name”, “S3 URL” of the source file and “Data Format”:
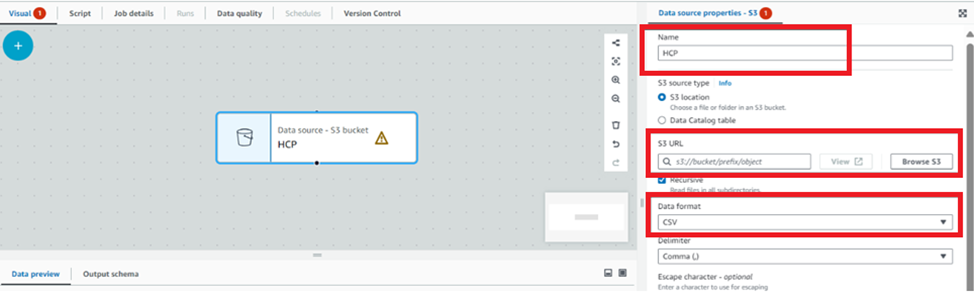
viii. Repeat the previous step for our other source, the “Sales dataset”.
ix. Now, let’s focus on the main part of this project: our data quality stage.
- Under “Nodes”, “Transform” section, select “Evaluate Data Quality”.
- Now to configure our input data sets, select “Evaluate Data Quality” entity from the visual interface and under properties, under “Node parents” select both the input datasets.
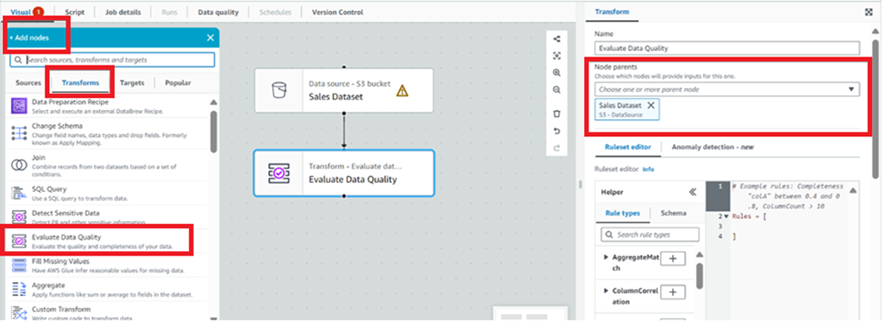
3. Defining Data Quality Rules:
Let us begin exploring rules and how to write them.
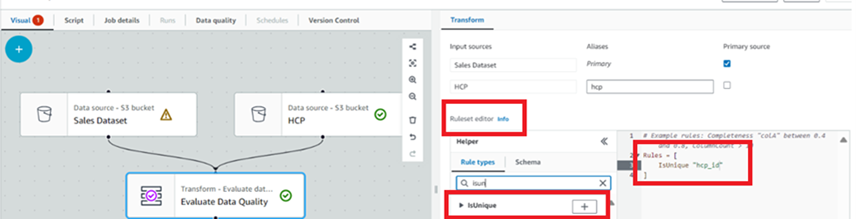
a) Under the “Ruleset editor”, we can see the “Rule Types” tab. This is a superset of 25+ pre-written rules which can re-used to work on our datasets.
i. We had planned to execute a couple of rules, one of them was unique HCP ID in “HCP Dataset”.
- We can navigate to “Rule Types”, search for “isunique”.
- Click on the plus sign next to the rule. This will add the rule to the rules list of the right-hand side. Now we can edit the rule to add our column.
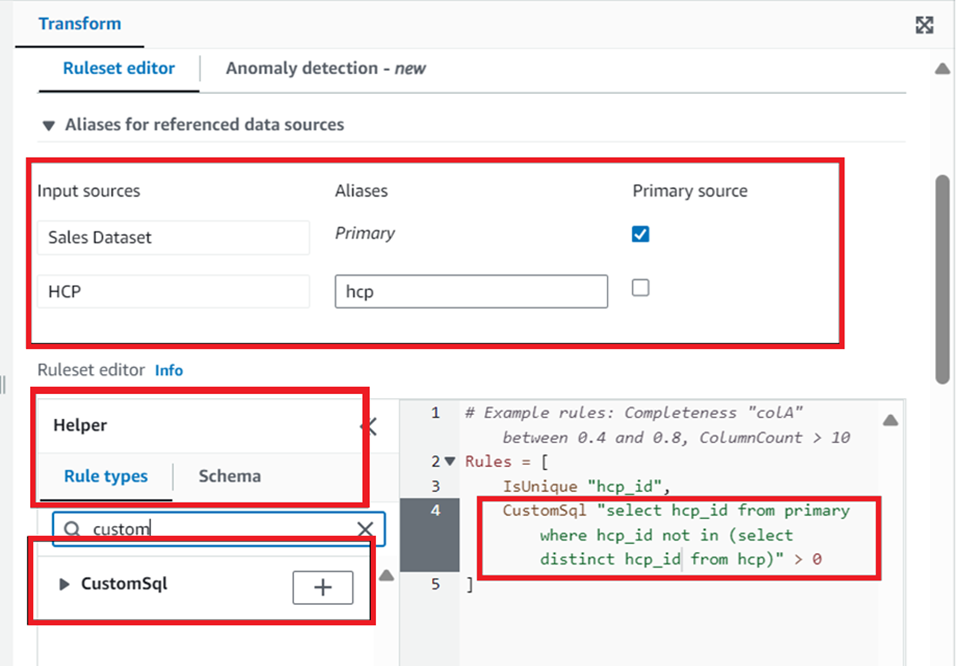
b) The rules are not limited to these pre-written ones, we can write our own custom SQL to execute some of the more complicated rules. Like – “hcp_id” in “Sales dataset” should match with “hcp_id” in “HCP Dataset”
i. To implement this rule, we can navigate to “Rule types”, search for “customsql”.
ii. Click on the plus sign next to the rule, then edit the rule to write our SQL.
- Before writing the SQL, let us check what our input tables are aliased as, under “Input Sources”. Post this we can write our code to find any “hcp_id” which is not in the “HCP Dataset”
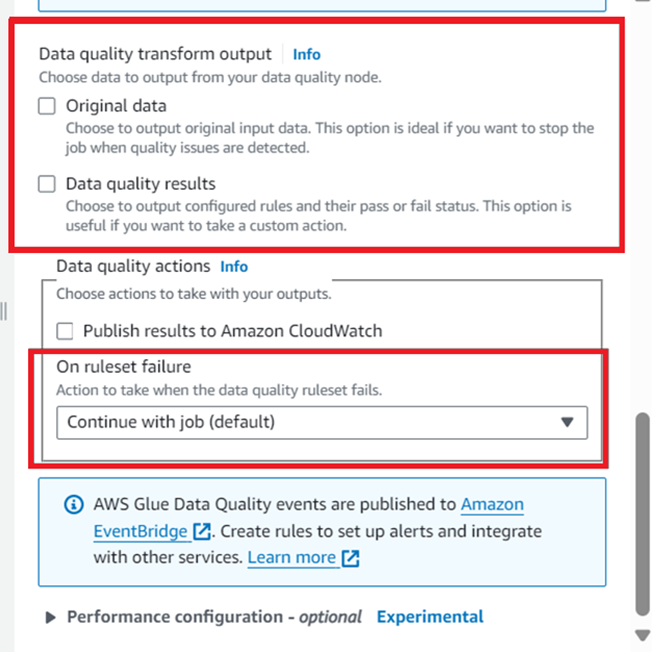
4. Handling Rule Outcomes: What Happens Next?
a) Now that we have implemented our rules, the question is what happens when they pass/fail.
b) We have three options:
- We can continue with the job regardless of the results.
- Fail the job without loading the data to target.
- Or fail the job after loading the data to target.
c) We also have the option to add audit columns to our data, indicating if any data row failed and, if so, which rule caused the failure.
d) For this example, we will fail our job after loading the data in case the rules fail. We are also writing the rule-level outcomes to a target S3 location.
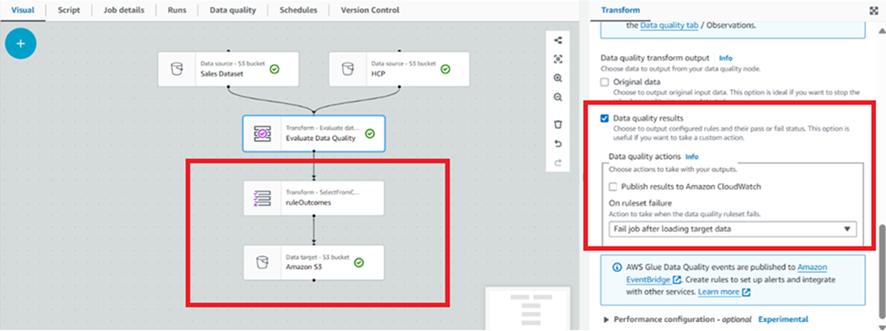
e) The target S3 is configured the same way we configured the source S3— from “Add Nodes”, under “Target” tab, select S3 and configure the URL you want to write to.
5. Saving and Running Your Data Quality Job
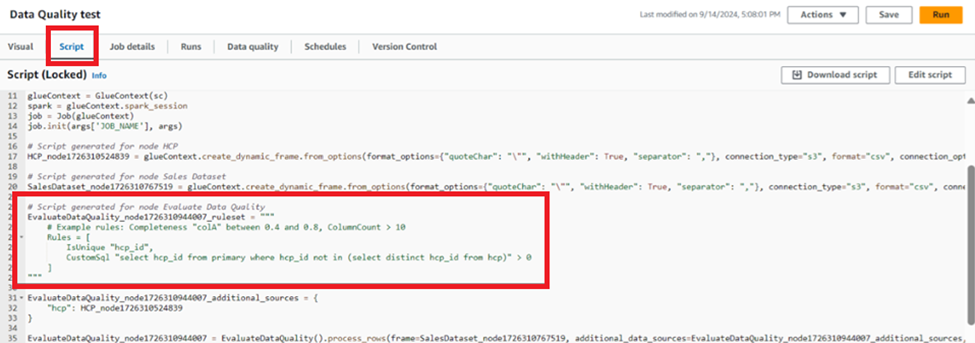
Save the job, and if you move to the “Script” tab, you will see that Glue has transformed our GUI into code.
a) Run the job. Notice that our job fails due to not passing the DQ rules.
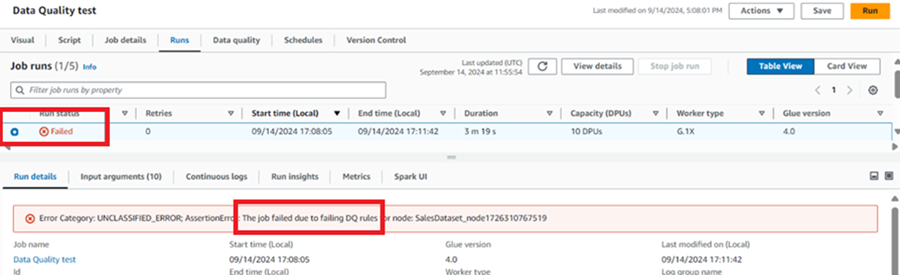
b) To find the reason for this failure, we can download the files we wrote to our target S3 bucket.
After configuring our data quality rules and running the job, you might be surprised to learn that the entire setup took just 15 minutes. This efficiency is one of the standout features of AWS Glue.
AWS Glue Data Quality is cost-effective and only incurs the same cost as your Glue Job, with just the additional runtime for executing the rules.
For more details on pricing, you can visit the AWS Glue Pricing page.
Beyond the immediate benefits, AWS Glue Data Quality also allows you to test data at rest and data quality can be configured with the Glue Data Catalog.
Need help with implementation?
If you need help with implementation, our team is here to assist. We specialize in designing and deploying data solutions tailored to your unique needs, allowing you to maximize the power of AWS services like Glue.
Contact us today and let’s unlock the full potential of your data together.

