
Evolving from cost centers to innovation powerhouses
in manufacturing
with data mesh architecture and GenAI
Real-time streaming analytics has revolutionized how businesses handle and process data. Unlike traditional batch processing, real-time analytics enables immediate data processing, allowing companies to respond to events as they happen. This shift is driven by the need for immediate insights and faster decision-making, crucial in today’s fast-paced business environment.
Real-time streaming analytics involves continuously processing data as it is generated, ensuring near zero latency from origin to destination. This allows businesses to analyze and act on data instantly.
For instance, a telecom company can analyze customer care conversations in real-time to provide instant feedback and sentiment analysis, significantly enhancing the customer experience. Immediate insights help companies address issues promptly, optimize operations, and improve service delivery.
Applications and use cases
Real-time streaming analytics has many applications across different industries:
● Telecom: Real-time analytics track customer journeys, manage network outages, and perform feature engineering, improving service quality and customer satisfaction.
● E-Commerce: Real-time clickstream analytics tracks user behavior, providing personalized recommendations and improving customer engagement, leading to higher conversion rates and retention.
● Finance: Real-time fraud detection systems analyze transaction data instantly, identifying suspicious activities and reducing the risk of financial crimes. This helps protect customers and maintain trust.
● Retail: Real-time analytics in retail can track customer movements and preferences in-store, enabling personalized marketing and inventory optimization to improve customer satisfaction.
Challenges in traditional on-premises solutions
Traditional on-premises solutions come with several challenges. While capable of both batch and real-time processing, these systems often struggle with the demands of real-time analytics due to:
● High costs: Licensing and support for on-premises solutions are expensive. Maintaining legacy code, such as C++/SPL, requires specialized skills and resources, driving up costs.
● Scalability issues: On-premises solutions struggle with scalability, particularly low latency and high throughput jobs. Outdated auto-scaling options limit performance and adaptability to changing workloads.
● Innovation constraints: Limited product releases and innovation cycles make it difficult for businesses to stay competitive and optimize operations effectively. These constraints hinder the ability to implement new features and improvements swiftly, affecting the performance and efficiency of real-time processing systems.
Below is a more detailed comparison between both highlighting the benefits of cloud over on-premise solution:
| Feature | Benefits with Google Cloud | Challenges with On-premises |
|---|---|---|
| Cost | Lower initial costs, pay-as-you-go model. | High upfront costs (hardware, licenses). Ongoing maintenance |
| Scalability | Virtually unlimited scalability. Auto-scaling as needed. | Limited by hardware. Scaling requires new purchases. |
| Maintenance | Managed by the cloud provider with automatic updates. | Requires in-house IT for maintenance and updates. |
| Deployment time | Rapid deployment, ready in minutes or hours. | Long setup times for hardware and infrastructure. |
| Security | Cloud providers offer built-in security, but users must secure their data. | Entirely the responsibility of the organization. |
| Disaster recovery | Built-in options with automated backups and redundancy. | Complex, expensive disaster recovery solutions required. |
| Global reach | Global infrastructure with low-latency access worldwide. | Limited to physical data centers. Global reach is costly. |
| Capacity planning | No upfront planning required. Resources adjust automatically. | Requires capacity estimation and hardware purchases. |
| Updates | Automatic updates without service interruption. | Manual updates, often causing downtime. | Performance | Optimized global performance. | Lower latency for local users but limited global performance. |
| Compliance | Providers offer compliance certifications, but users still ensure data use compliance. | Full responsibility for meeting regulatory compliance. |
| Innovation | Access to cutting-edge services like AI, ML, and analytics. | Slower access to new technologies. | Backup and redundancy | Automated backups and multi-region redundancy. | Requires separate, costly systems. | Latency | Optimized for global reach but may have slightly higher local latency. | Lower latency locally but higher for distant users. |
Transition to cloud-based solutions
Robust cloud-based solutions like Google Cloud Dataflow offer an alternative to traditional on-premises setups. They are better equipped to handle the dynamic nature of real-time data processing and offer greater flexibility and scalability.
● Cost efficiency: Moving to a cloud-based solution eliminates hefty licensing fees. Instead, companies adopt a pay-as-you-use model, which is more cost-effective and scalable. This shift allows for better financial planning and resource allocation.
● Scalability: Google Cloud Dataflow supports horizontal and vertical autoscaling, allowing businesses to optimize resource use and maintain high performance.
● Seamless performance: Google Cloud Dataflow, a managed service for Apache Beam, provides comprehensive support for streaming performance, ensuring seamless data processing and integration with existing systems.
Architectural highlights of Google Cloud implementation
Fractal recently worked with a US-based telecom company transitioning from IBM Streams to Google Cloud using our unique architecture. Implementing real-time streaming analytics on Google Cloud involves several key components and design considerations, which we’ve meticulously designed:
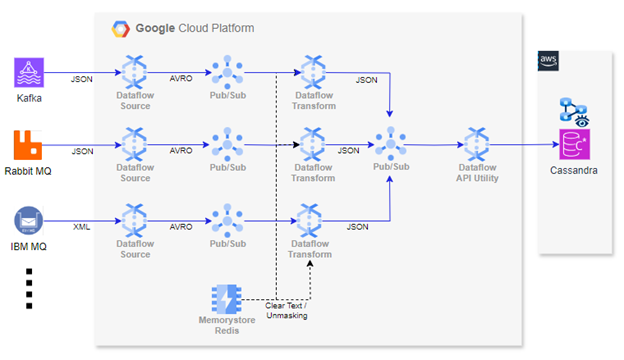
Data pipeline design
Data ingestion is handled through PubSub, with Dataflow jobs processing and temporarily landing the data in PubSub in AVRO format. PubSub is selected for its reliability and scalability, ensuring strict schema typing with AVRO, which provides data integrity and seamless integration. While processing, MemoryStore is leveraged to unmask critical information securely. Several architectural and service-level optimizations are employed across PubSub, Memory Store, and Dataflow to handle scalability, high availability, fault tolerance, dead letter queues, and ensure consistent data processing without loss.
Observability and monitoring
Google Cloud provides robust observability solutions, including Dataflow Job UI and cloud monitoring, which allow businesses to monitor pipeline health, set custom metrics and alerts, and ensure smooth operation. Integration with third-party tools like New Relic or Grafana further extends monitoring capabilities, enabling a comprehensive observability strategy. Disjoint observability can be challenging, but integrating cloud monitoring tools ensures cohesive monitoring across different systems. Advanced Dataflow monitoring techniques include custom logging and metrics to track pipeline performance and diagnose issues in real-time. Additionally, job labels facilitate FinOps monitoring and enable business classification of workloads, providing deeper insights into operational costs and resource allocation.
Integration with external systems
Our architecture supports seamless integration with external databases, such as AWS Cassandra, through REST API calls over Google Cloud egress. Additionally, model calls are made using REST APIs, employing effective exponential backoff techniques to minimize data loss. This approach enables businesses to maintain data flow across different systems without compromising performance or scalability.
Benchmarking and performance optimization
Benchmarking is essential to ensure optimal performance of real-time streaming analytics:
● Framework comparison: We chose Apache Beam over Flink due to its unified pipeline capabilities, supporting both batch and real-time processing, and benefiting from better community support and management as a managed service within Google Cloud. This flexibility makes it ideal for building architectures that serve as a north star for data ingestion, processing, and inference generation, accommodating both batch and real-time workloads holistically.
● SDK selection: After thorough benchmarking, we selected the Java SDK over Python for its superior throughput and latency performance. Multiple volumetric integration tests were employed to measure performance, including the use of cache, intermediate data persistence, and egress model or data sink REST API calls. Benchmarks consistently showed that the Java SDK handled higher transaction volumes with lower latency.
● Template optimization: Flex templates create dynamic, parameterized jobs based on standard core functionality, making managing and deploying various jobs easier. Dataflow Flex Templates allow for more customizable and reusable pipeline templates.
● Code Design as Framework – Code framework was orchestrated and classified in logical and business specific java modules leveraging various design patterns and utilities for ease of development, maintenance, reusability and deployments.
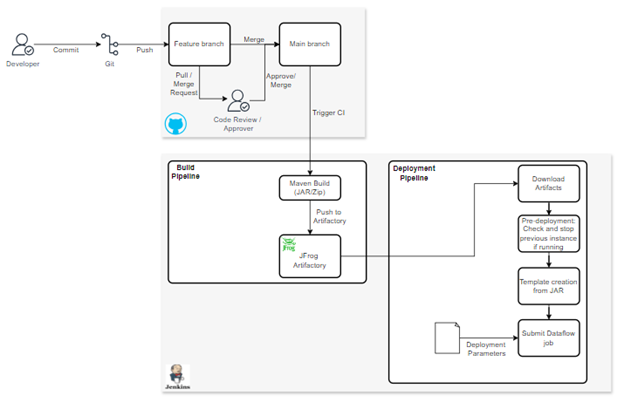
CI/CD enablement for real-time streaming use cases
Continuous Integration and Continuous Deployment (CI/CD) are crucial for managing real-time streaming analytics workflows:
Pipeline setup
Our developers work collaboratively using feature branches and merge requests, ensuring that code is thoroughly tested and reviewed before deployment. The code moves through the development, QA, and production stages, maintaining high standards of quality and reliability.
Artifact management
The build pipeline packages the code into versioned artifacts, which are then released through the deployment pipeline. This ensures consistent and reliable execution of real-time jobs, minimizing downtime and maximizing efficiency. Tools like Jenkins manage these CI/CD pipelines.
Future outlook and trends
The future of real-time streaming analytics is filled with opportunity, as several emerging technologies are set to enhance its capabilities further:
● AI integration: Integrating GenAI and large language model (LLM) capabilities offered by Google Cloud, leveraging Vertex AI APIs, can significantly extend real-time use cases. This integration supports Retrieval-Augmented Generation (RAG) based architectures and enables optimal prompt-based searches and inferences, enhancing the capabilities of real-time analytics.
● Enhanced observability: Tools like Grafana and DataDog offer advanced reporting and monitoring capabilities, providing deeper insights into pipeline performance and enabling proactive management. (Ensuring data security is critical, with robust measures like data encryption and access controls.) These frameworks also allow seamless integration of dataflow custom business metrics and counters.
● Cost management strategies: Strategies for managing costs in Google Cloud include setting budget alerts and optimizing resource usage through detailed cost analysis.
Conclusion
Real-time streaming analytics offers unparalleled benefits for businesses, from improved customer service to enhanced operational efficiency. By transitioning to cloud-based solutions like Google Cloud, companies can overcome the challenges of traditional on-premises setups and leverage cutting-edge technologies to stay ahead in a competitive market. Our unique architecture, tailored specifically for real-time streaming analytics, enhances these benefits by providing a robust, scalable, and flexible solution.