
IVA Geo
The Zero-Shot Approach
by Fractal
Data scientists and analysts have a process-heavy job of cleaning and managing data. But imagine there was a smart, easy-to-use system that solved the challenges they — and, by extension, your enterprise — faced. For instance, multiple stakeholders can promptly access the required data without relying on analysts for preparation, thereby greatly reducing analysis time. This empowers individuals, regardless of their specialized skills, to efficiently access and utilize the data, thereby enhancing accessibility and efficiency across diverse industries
Introducing Genesis-SQL-GPT
Our dedicated team is working on the solution “Genesis-SQL-GPT.” This tool leverages Generative AI (Gen AI) technology, empowering users to interact conversationally with databases. In other words, users can ask questions to retrieve information.
It can be applied across any sector that deals with structured data. For instance, Consumer Packaged Goods (CPG) companies, traditionally reliant on Business Intelligence (BI) experts, can now automatically generate queries to analyze sales and distribution data. Wealth management companies can enable their sales executives to track metrics and asset holdings, make decisions efficiently, and increase engagements, all through quick and intuitive queries.
How it works
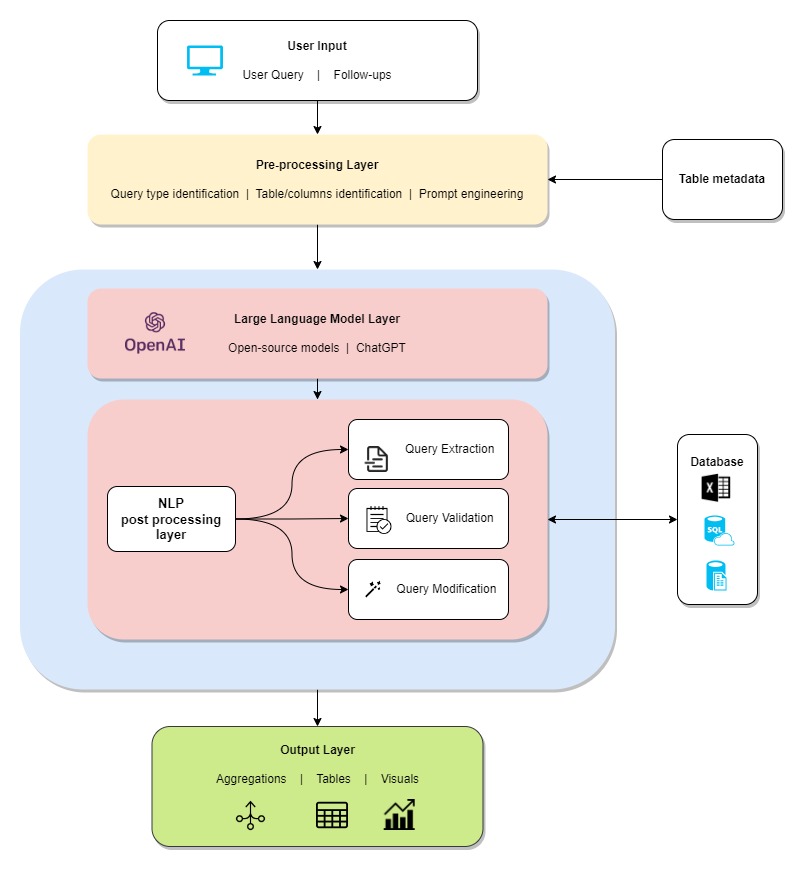
SQL-GPT harnesses Generative AI (Gen AI) to process information and answer questions. If a user enquires something specific, such as “How many employees who report to Matthew are located in Mumbai?” it will search through stored information, pick out the accurate details, and then organize them to find the answer and provide the answer in natural language. In this case, it might reply, “There are 6 people who report to Matthew in Mumbai.”
Traditionally, this question would require manually filtering and counting in an Excel file or writing SQL queries in a database. However, SQL-GPT makes this much simpler. It sends the question to the backend, validating it to ensure the required data exists. Metadata, including brief descriptions of tables and columns, is sent to the Gen AI model to create an equivalent SQL query. This query is then validated to ensure it makes sense and relates to existing data, and the output is then returned to the user. This process is accomplished in a simple five-step method:
1. Query classification
SQL-GPT classifies user input into one of four categories, determining whether the text is a greeting, a valid business query, a question related to the database, or an input that falls under other miscellaneous categories.
2. Text-to-SQL
The natural language query is then converted into an equivalent SQL query. This is done by leveraging the ability of large language models to generate a SQL query when given a question and the relevant table schema and metadata for their columns. Prompt engineering plays a vital role in this step.
3. Automatic query validation
The automatic query validation feature helps validate if the generated SQL query is syntactically correct. This validation process checks several aspects, such as whether the referred table and columns exist and whether the data types match (like ensuring a name matches a column with text fields rather than number fields). Once validated, the SQL query is further checked for correctness.
4. Correction
A smart query correction module is activated if an SQL query fails to find certain specific values in the database. This guides the user to modify the SQL query to work as intended. A fuzzy logic algorithm filters the closest possibilities, and the system might prompt the user to choose among the possibilities via a hassle-free UI experience.
5. Result output
Once the relevant data has been sourced, the system automatically creates charts to help visualize the information. The system intuitively picks the best way to represent the information based on the nature of the data. SQL-GPT currently supports four types of charts: line charts, bar charts, histograms, and scatter plots. The choice of the chart is determined by the data values and types, allowing for an instant, suitable visual representation without needing any input from the user.
How Fractal is Leading the Way
Our design philosophy centers around the customer’s needs and challenges. We recognize that users may not always know what information is available in a database, so we’ve built a system that assists them in understanding what data is there. Unlike some approaches that rely heavily on generative AI to automate everything, we prefer to strike a balance. We use AI to do minimal work, while our team handles the more complex tasks. This approach gives us more control and confidence in the system.
Capabilities that we’ve included to make the tool more user-friendly include the following:
Follow-ups
One key feature of SQL-GPT is the ability for the user to ask follow-up questions. The system considers the past and present queries, providing additional context to the GenAI model. Leveraging the chain of thought sequential approach ultimately leads to a final SQL query that can be triggered in the system, providing the user with a comprehensive answer.
KPI configuration
Our system enables users to define their own custom Key Performance Indicators (KPIs) or metrics in an Excel file, complete with instructions for calculation. Once uploaded, the system can automatically recognize and follow these instructions to answer specific questions.
This functionality not only increases the system’s utility but also saves users time and effort, eliminating the need for complex column manipulations across multiple Excel files. We also support a Data Loader feature that allows users to upload Excel files quickly and interact with them immediately without a complicated setup process.
Complicated queries
SQL-GPT is capable of handling complex queries, including those that involve connecting multiple tables or using nested queries. Since users may have hundreds of tables with many columns, providing the entire database to our AI model is impossible, especially given a token limit for processing. Instead, it detects which columns are relevant to answer the query and only provides that sample metadata to the model.
Scalability and performance
Handling large databases and high volumes of queries in terms of scalability and performance involves two main components:
1. Large numbers of simultaneous queries: We use Kubernetes clusters, an open-source system for deployment and management. Each request is treated as a separate thread, allowing for concurrent processing.
2. Simultaneous requests to the SQL databases: We choose databases like PostgreSQL that have built-in functionality to handle multiple requests simultaneously.
This two-pronged approach ensures efficient handling of large databases and a high volume of queries.
Speed
To handle the computational demands of SQL-GPT, we deploy two approaches depending on the specific model. When using open-source models, GPUs can be leveraged to speed up inference time. Using third-party applications like ChatGPT, the system can be built at the CPU level without requiring specialized hardware infrastructure. In both cases, techniques to shrink model sizes can be applied to ensure smooth performance. Additionally, if the SQL database is extensive, indexing retrieves information, making the system efficient and responsive quickly.
Security
Our system offers several protective measures to handle security and privacy concerns, especially when dealing with sensitive data. First, we can use in-house open-source models hosted on our infrastructure instead of relying on third-party APIs. This keeps everything under our control, eliminating most security concerns. Second, our system doesn’t send any sample or real data to the bot. Instead, we provide metadata, including tables and column descriptions, to generate queries, ensuring that actual data remains secure. Lastly, if the client uses third party infrastructure like Azure, additional security measures are in place to keep all operations within the client’s controlled environment, further safeguarding the information.
Assessing System Performance and Accuracy in SQL Query Generation
To ensure our system works correctly, we have created custom data sets containing carefully crafted queries and their correct answers for testing. Additionally, we use open-source benchmarks such as those designed for structured database querying. Our validation involves benchmarking our system against these open-source data sets and our handcrafted tests. Through the amalgamation of established industry standards and our distinctive insights and experiences, we can precisely assess our system’s proficiency in producing SQL queries while upholding an unparalleled standard of quality and dependability.
However, while our system is designed to simplify tasks, it’s not yet 100% accurate. If the system fails, experts who understand SQL will still be needed to debug and improve it. Therefore, it won’t eliminate the need for technical expertise… Yet.